本文为自己总结,不保证正确,但保证有实验验证。
几个小概念
字符集合(Character set)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等,简单理解就是一个字库,与计算机以及编码无关。比如古代的苏州码子就算一种字符集合。

字符编码集(Coded character set):可以理解为键-值对,一个字符对应一个码点。
字符编码(Character Encoding):所有数据在计算机上存储,都是以二进制01的格式进行存储。为了存储字符,需要一种映射关系将字符与码点进行对应。
字符集(Charset):可以认为字符编码集和字符编码构成字符集。
以上几个概念并不用严格区分,根据语境的不同含义可能也不同。
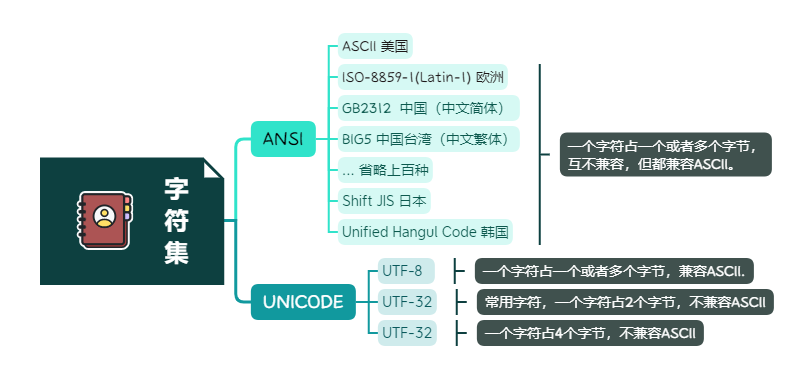
字符集
字符集的分类
常见的字符集可分为以下几种:
ASCII码
字符集:一共有128个字符的编码,基于拉丁字母,主要包括英语和西欧语言字符。
编码形式:ASCII编码十分简单,占1个字节。由于只有128个字符且1个字节最多可以表示256个数字,所以将码点对应的十进制转为无符号二进制数后添0构成1字节即可。所以,所有的ASCII码都以0开头,对应十进制数为正数。
GBK
字符集:GBK字符集共收录21003个汉字,包含国家标准GB13000-1中的全部中日韩汉字,和BIG5编码中的所有汉字。
编码形式:兼容ASCII码,一个英文占1个字节,一个汉字占用2个字节。全部字符15位即可表示,转成二进制编码后高位字节最高位固定添1即构成GBK码。所以,汉字字符对应字符为负数,英文字符对应字符为正数。
Unicode编码
字符集:Unicode又称为统一码、万国码、单一码,是国际组织制定的旨在容纳全球所有字符的编码方案,包括字符集、编码方案等,它为每种语言中的每个字符设定了统一且唯一的二进制编码,以满足跨语言、跨平台的要求。
编码形式:
- UTF-16:用2-4个字节保存。
- UTF-32:固定使用4个字节保存。
- UTF-8:用1-4个字节保存。兼容ASCII码,一个英文占1个字符,一个简体中文占3个字符。将码点转为无符号二进制数后填入1110XXXX-10XXXXXX-10XXXXXX即可。所以,汉字字符对应字符为负数,英文字符对应字符为正数。
Java中的编码
内码
内码是程序内部使用的字符编码,特别是某种语言实现其char或String类型在内存里用的内部编码。Java规定了字符的内码要用UTF-16编码。
外码
外码是程序与外部交互时外部使用的字符编码。java中外码中char使用UTF-8的方式编码
一个实验[1]
| Char | U10 | U16 | GBK |
|---|---|---|---|
| 中 | 20013 | 4E2D | D6D0 |
| 涓 | 28051 | 6D93 | E4B8 |
Java的char型采用的是Unicode的标准,所以char的字符,转为int型打印出来的数字,就是unicode字符对应的数字。
同时在对io流做操作时,如果以字符流做操作,并且创建io流时未指定charset的话,直接使用jdk属性file.encoding的值来做为default charset。
汉字”中”读出来的数据(UTF-8格式) 为-28 -72 -83
转换为二进制11100100- 10111000-10101101
由于file.encoding为GBK,所以按GBK解码,11100100-10111000为解码的第一位字符。
但Java无论是内码还是外码都采用Unicode编码,所以要进行映射,得到该GBK对应的汉字的Unicode码点, 11100100-10111000十六进制E4B8对应汉字:”涓”,对应Unicode编码十进制为28051,所以强转为int时打印值为28051。
最终结果就是,将“中”对应的前两个字节按照GBK解码,内部存储的值是解码后汉字代表的Unicode码点。
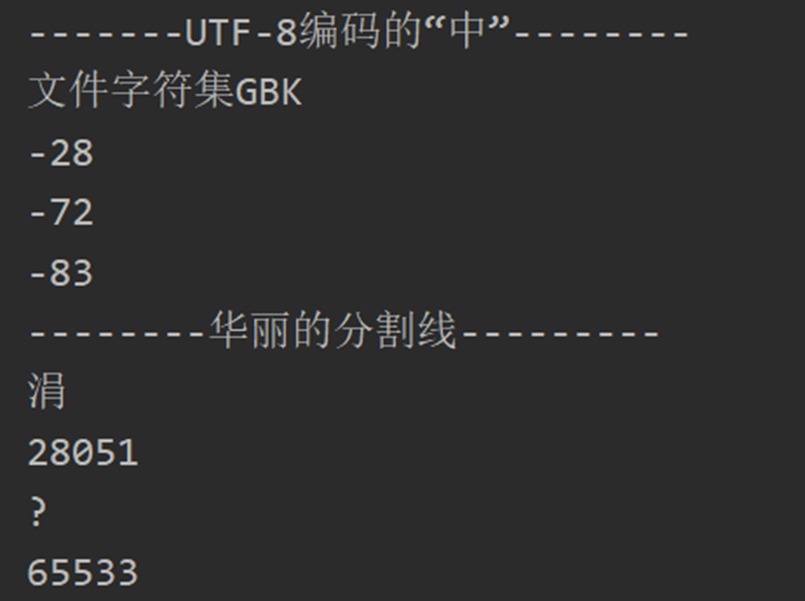
汉字”中”读出来的数据(GBK格式) -42 -48 D6D0所以强转为int时打印值为20013。
