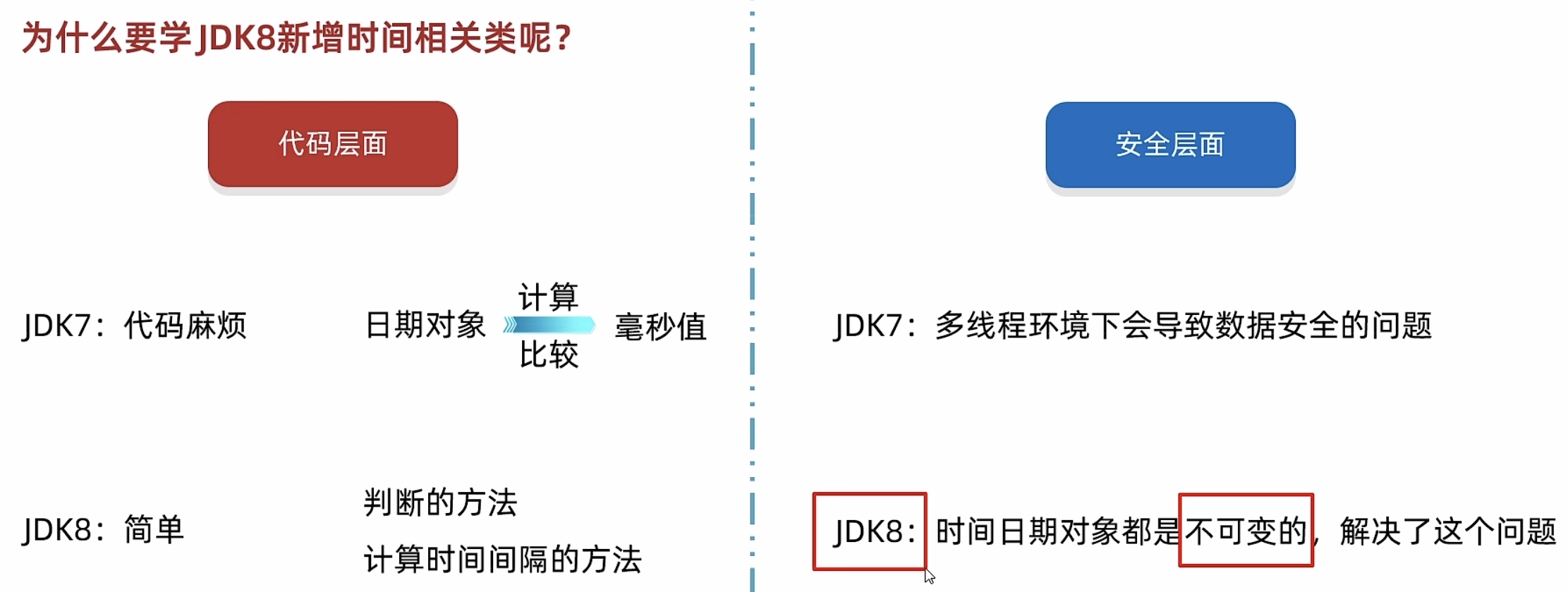
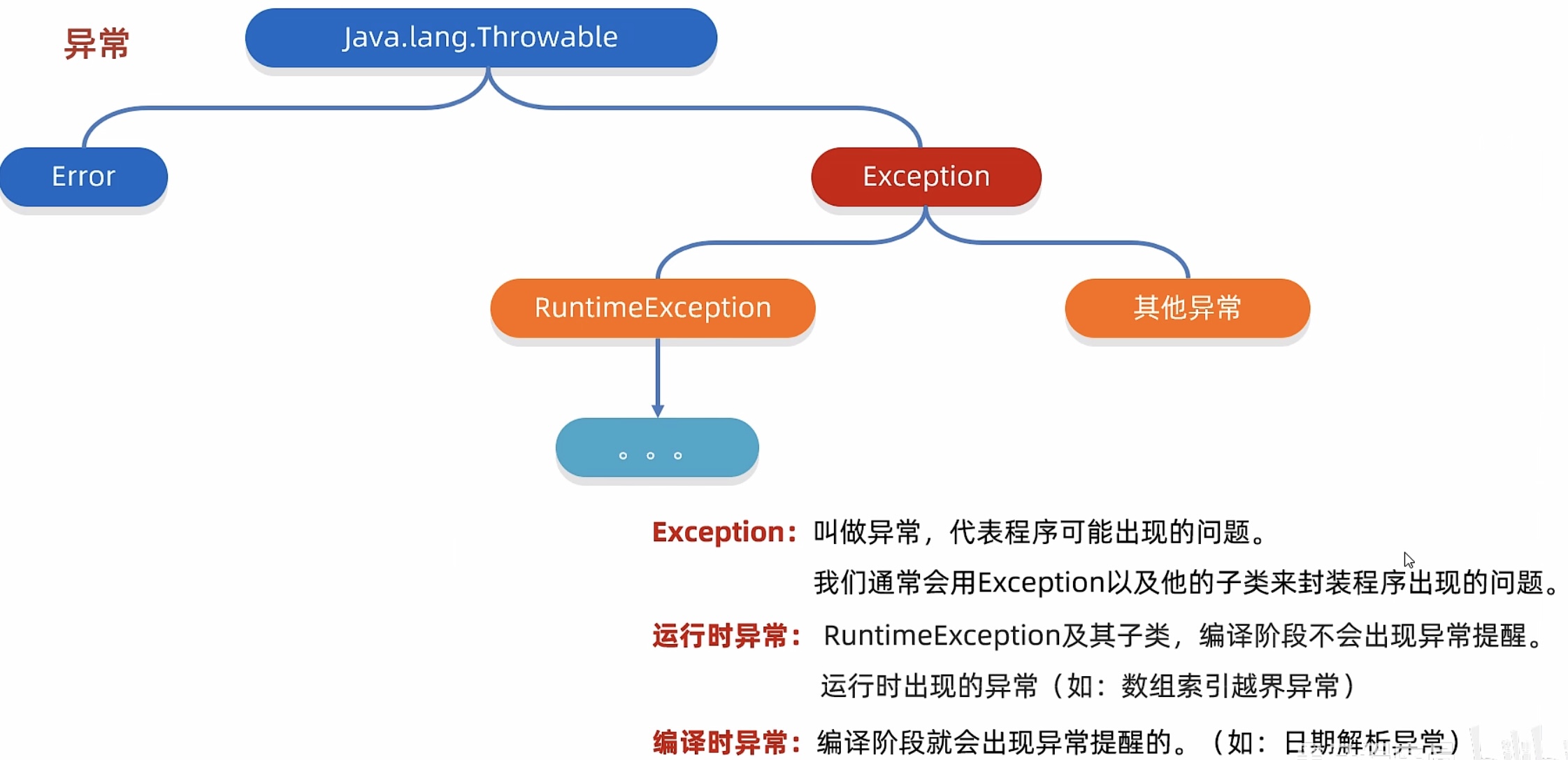
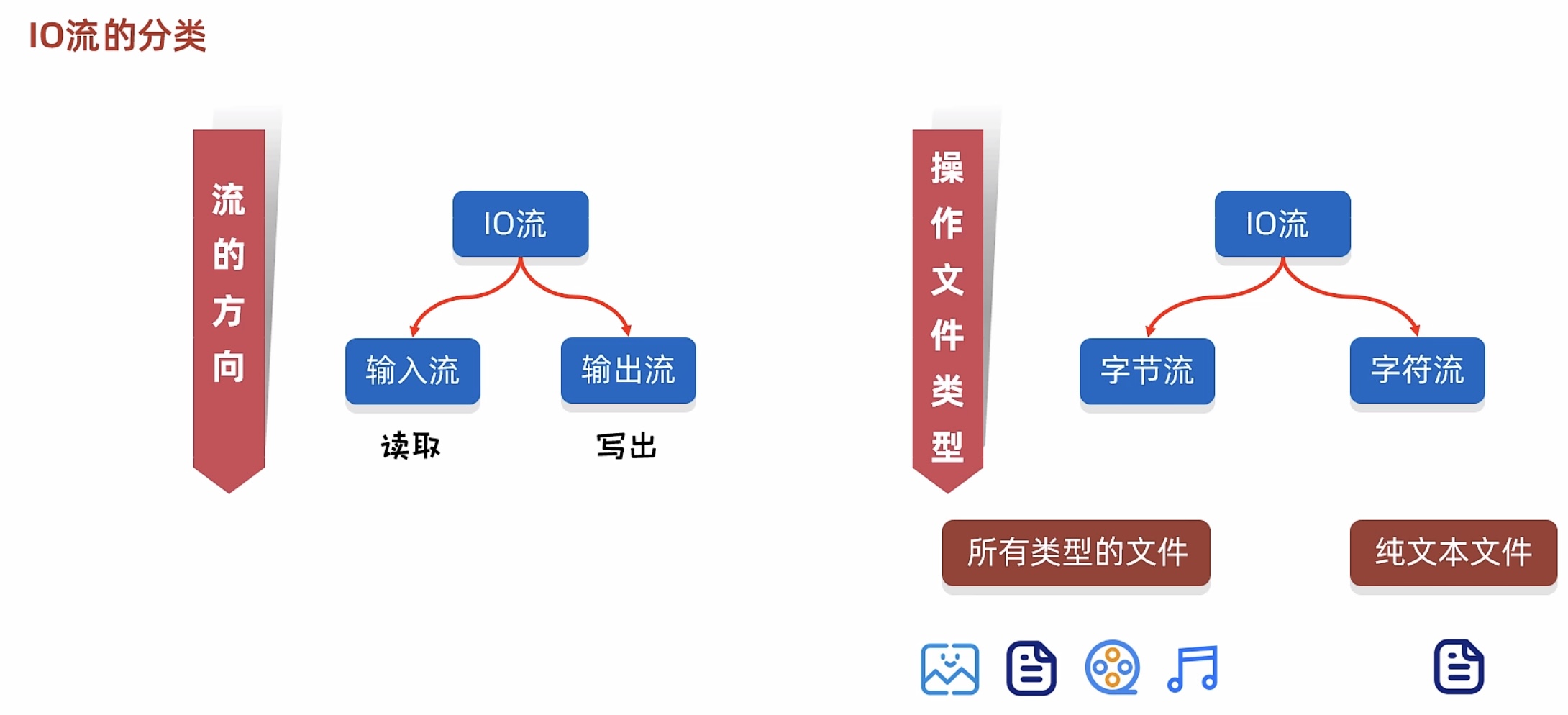
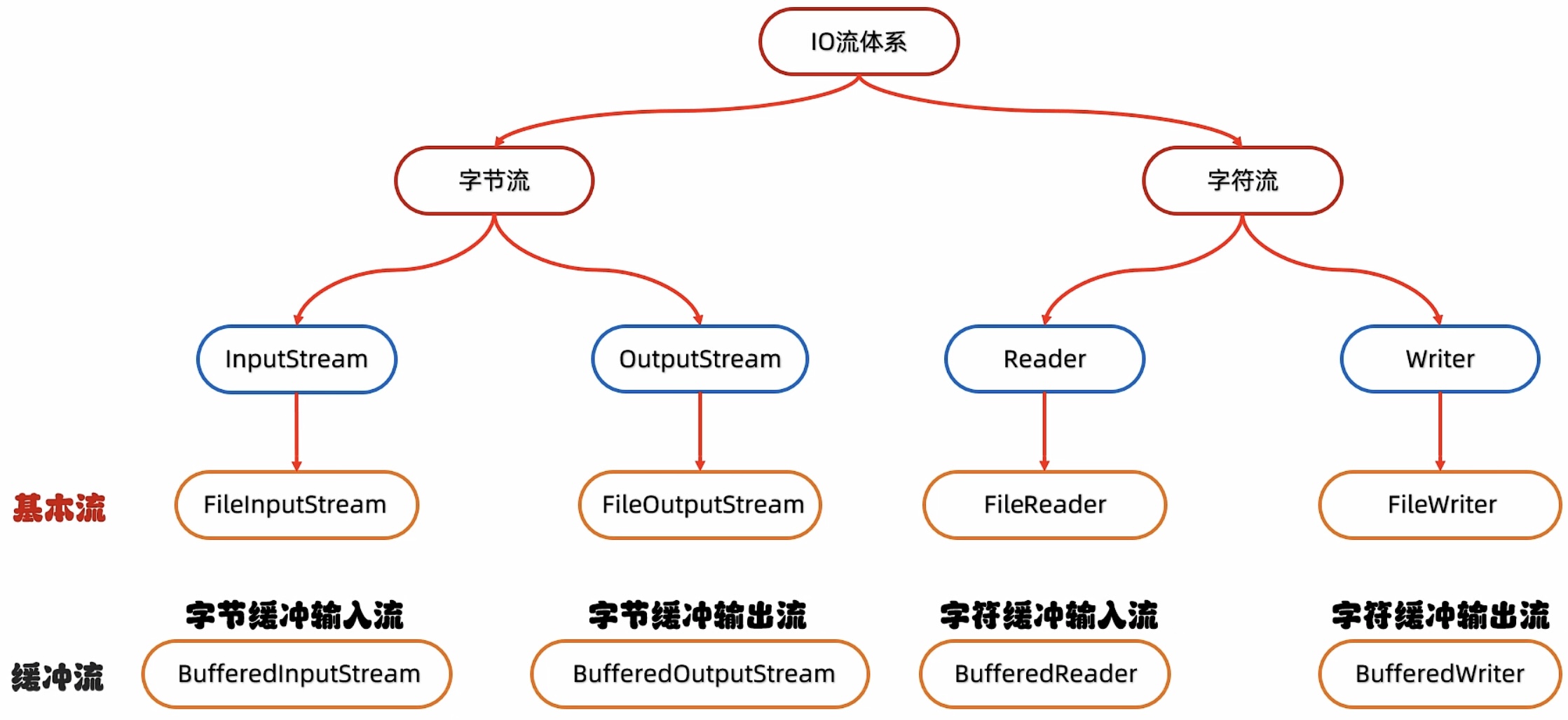
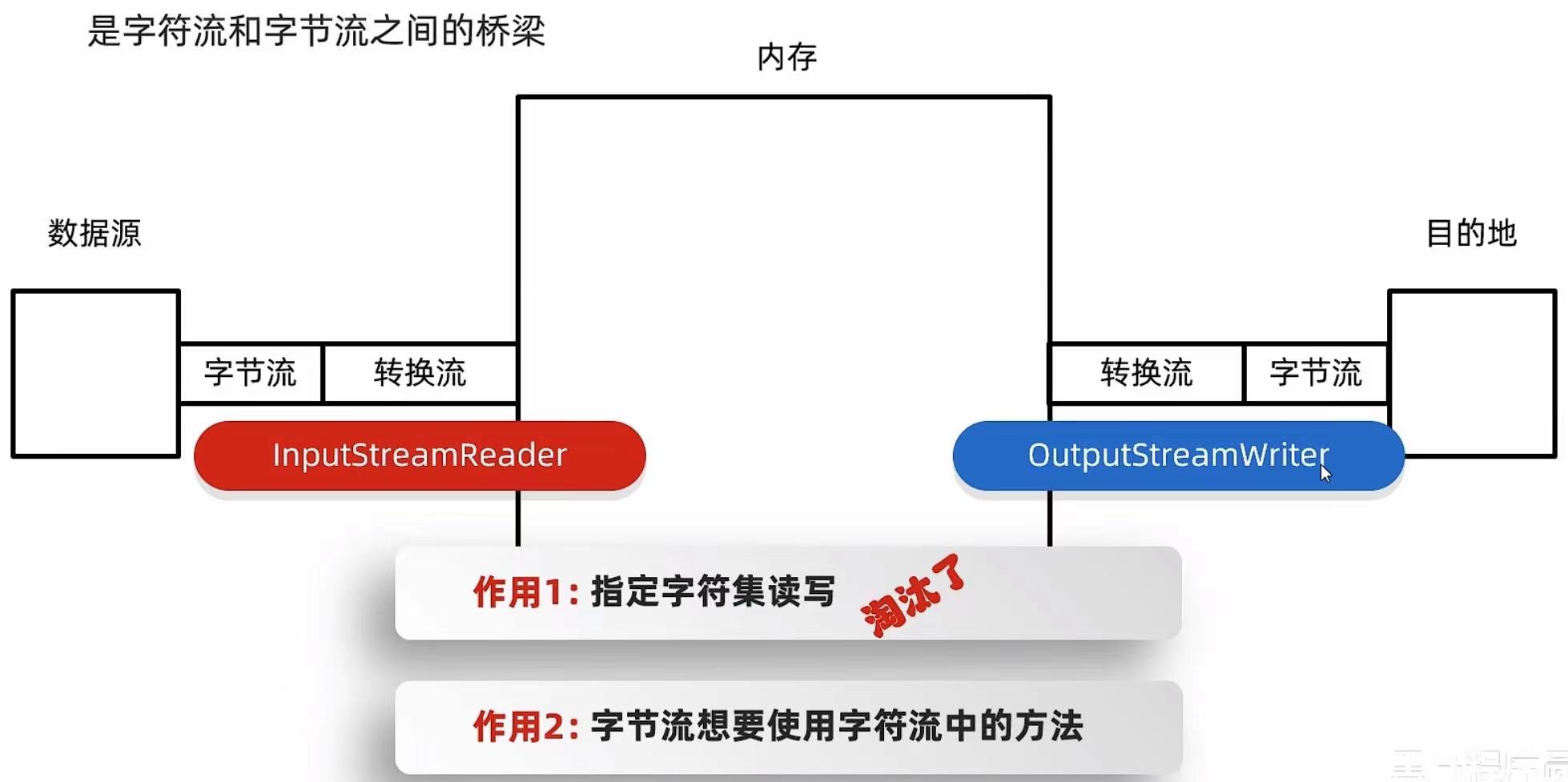
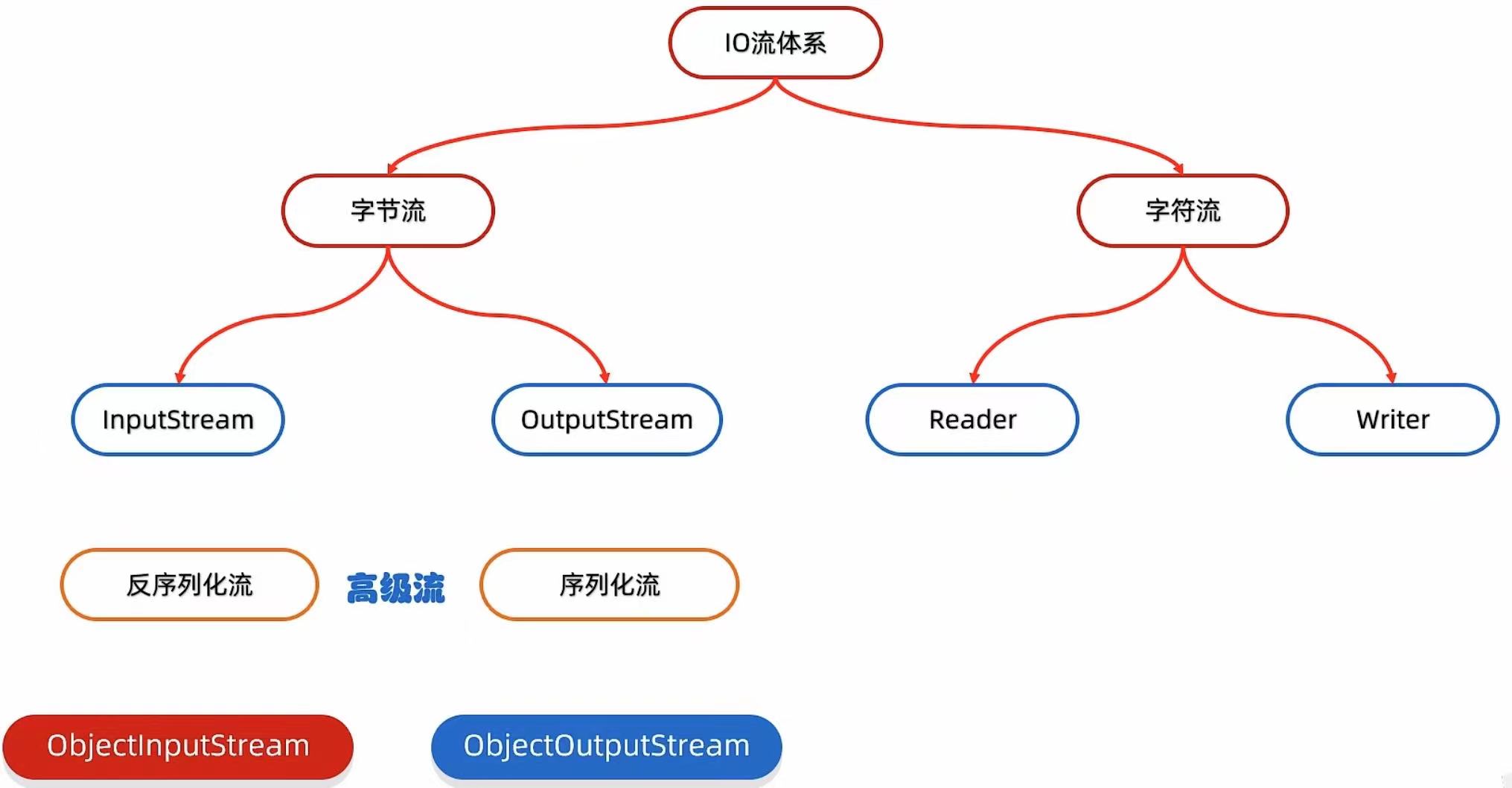
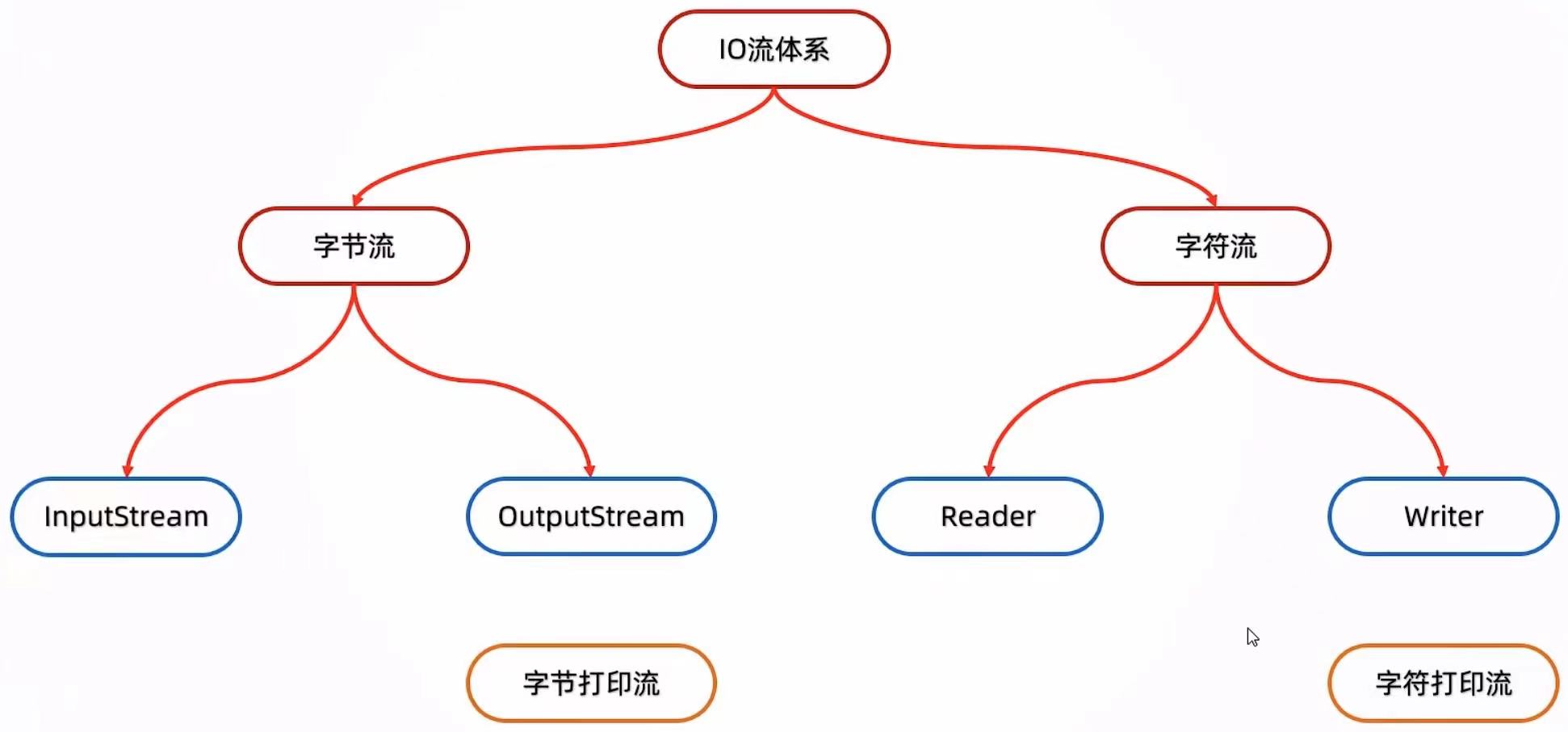
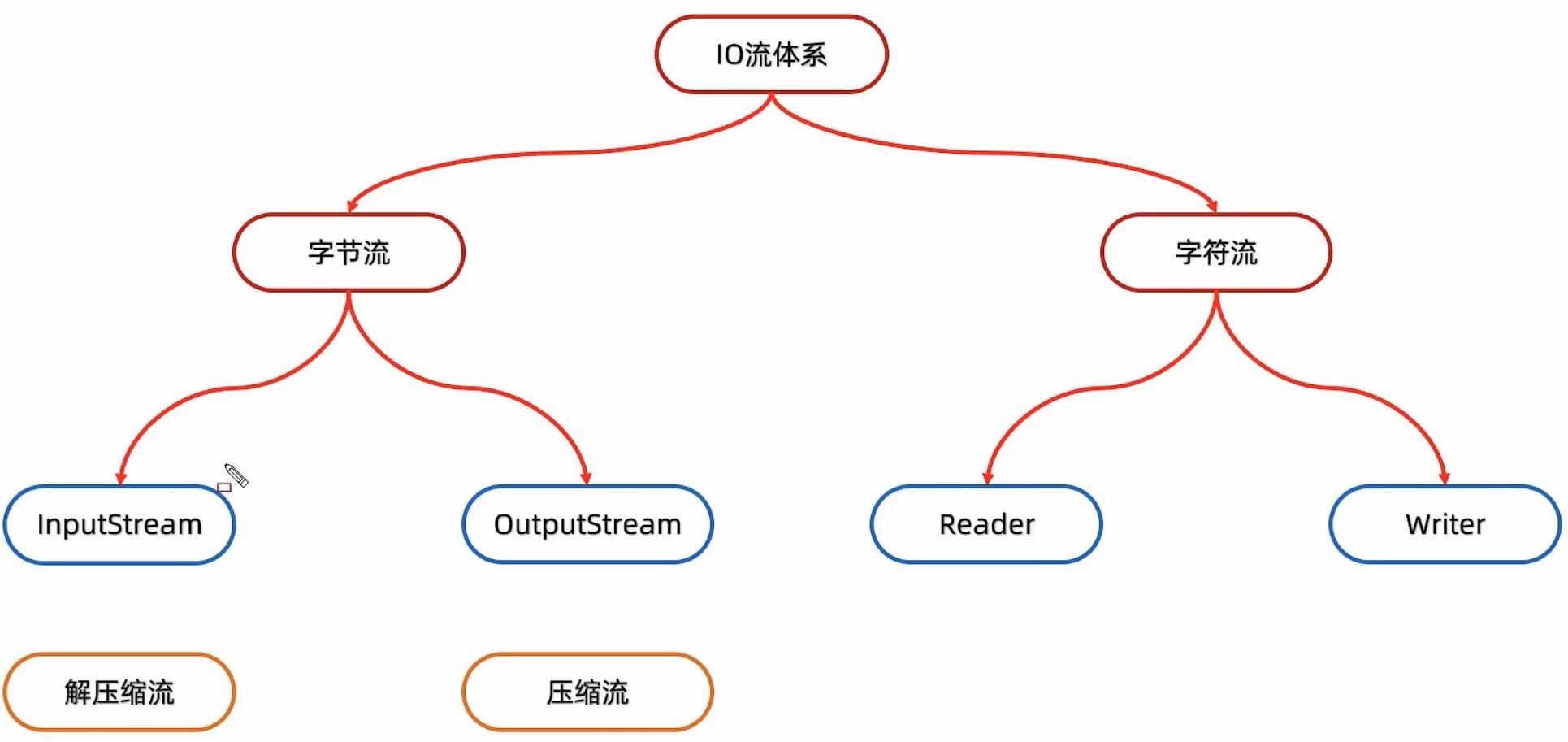
图形化界面的缺点:
CMD:在windows中,利用命令行的方式操作计算机。
可以打开文件,打开文件夹,创建文件夹等等。
打开CMD的方式:win+R
盘符名称+冒号:盘符切换。
dir 查看当前路径下的内容。
cd目录 进入单极目录。
cd.. 返回上一级目录。
cd 目录1\目录2\ … 进入多级目录。
cd\ 回退到盘符目录。
cls 清屏。
exit 退出命令提示窗口。[Windows系统不区分大小写]
假设QQ是经常要打开的文件,每次都开都要切换盘符,并且进入多层文件夹,非常麻烦。此时可以把QQ的路径记录在环境变量。参考Linux命令,理解环境变量的意义。
bin: 该路径下面存放了各种工具命令。其中比较重要的有:javac和java。
conf:该路径下存放了相关配置文件。
include:该路径下存放了一些平台特定的头文件。
jmods:该路径下存放了各种模块。
legal:该路径下存放了各模块的授权文档。
lib:该路径下存放了工具的一些补充jar包。
编写程序->编译->运行
编译:java是JDK提供的编译工具,利用这个工具可以把HelloWorld.Java编译成class文件。
运行:Java是JDK提供的一个工具,作用是运行代码。在当前路径下运行HelloWorld.class这个文件运行时不需要加后缀。
java5.0 第一个大版本
java8.0公司使用
java17.0教学使用
Java有三大使用平台:
Java SE Java语言的标准版,用于桌面应用的开发,是其他两个版本的基础。
Java ME Java语言的小型版,用于嵌入式电子设备或者小型移动设备。
Java EE Java语言的网站版,用于WEB方向的开发。适用于
浏览器+服务器开发。
java能做说明?
桌面应用开发 各种税务管理软件,IDEA,Clion 企业级应用开发(服务器) SpringCloud 移动应用开发 鸿蒙,andriod,医疗设备 科学计算 matlab 大数据开发 hadoop 游戏开发 我的世界 java为什么那么火?
Java的主要特性
面向对象 安全性 多线程 简单易用 开源 跨平台 Windows Mac Linux 高级语言的运行方式
编程:Java编写.java代码 编译:把.java转化成机器认识的过程 运行:让机器执行编译后的指令 高级语言的编译运行方式
编译型 C语言 整体翻译 解释型 Python语言 按行翻译 混合型 Java Java编译过程
==Java不是直接运行在系统中的,而是运行在虚拟机中的==
跨平台原理
Java跨平台原理
JVM(Java Virtual Machine):Java虚拟机,真正运行java程序的地方。
核心类库:Java事先写好的
JAVAC:编译工具
JAVA:运行工具
JDB:调试工具
Jhat:内存分析工具
JVM,核心类库和开发工具组成整体叫做JDK(Java Development kit),java开发工具包。
将运行需要的部分从JDK抽离出来,组成的部分叫做JRE(Java runtime Environment),java的运行环境。
单行注释
多行注释
文档注释
关键字:被Java赋予了特殊含义的英文单词。关键字字母全部小写。
class:用于创建/定义一个类,类是Java最基本的组成单元。
1
2
3
public class HelloWorld {
} HelloWorld就是类名
字面量就是告诉程序员,数据在程序中的书写格式。
Java字面量
拓展点:特殊字符
‘\t’ 制表符 在打印的时候,把前面字符的长度补齐到8或者8的整数倍。最少补一个空格,最多补8个空格。打印表格数据方便对齐。
‘\r’ \r后边的数字替代 这一行最开始的相等数目的数字。
‘\n’ 换行
变量:存储数据的小箱子。
变量的定义格式:
变量的使用方式:
变量使用的注意事项:
只能存一个值 变量名不允许重复定义 一条语句可以定义多个变量 int a = 10, b = 20; 变量使用之前一定要进行赋值 ==定义后就赋值== 变量的作用域范围 计算机有以下三类数据:
Text文本 包括数字、字母、汉字 Image图片 Sound声音 在计算中,任意数据都是以二进制的形式来存储的。
不同进制在代表的表现形式不同:
二进制在代码中以0b开头。 十进制不加任何前缀。 八进制代码中以0开头。 十六进制代码中以0x开头。 汉字编码:
GB2312:1981年5月发布的简体中文汉字编码国家标准。 BIG5编码,台湾地区繁体中文标准字符集。 GBK编码,2000年3月17日,包含上面两款全部汉字。 Unicode编码,国际标准字符集,世界所有语言的每个字定义一个唯一的编码。 图片数据:
分辨率,像素,三原色。
数据类型分为基本数据类型和引用数据类型。
Java基本数据类型
标识符就是给类、方法、变量等起的名字。
标识命令规则 —硬性要求
由数字、字母、下划线和美元符组成 不能以数字开头 不能是关键字 区分大小写 标识命令规则 —软性要求[见名知意]
小驼峰命令法:方法、变量规范1:标识符是一个单词的时候,全部小写。如name。 规范2:标识符由多个单词组成的时候,第一个单词首字母小写,其他单词首字母大写。如firstName。 大驼峰命令法:类名规范1:标识符是一个单词的时候,首字母大写,如Student 规范2:标识符由多个单词组成的时候,每个单词的首字母大写,如GoodStudent。 键盘录入介绍
java帮我们写好了一个类交Scanner,这个类可以接收键盘输入的数字。
使用步骤:
步骤一:导包 — Scanner这个类在哪 步骤二:创建对象 — 表示开始使用Scanner这个类 步骤三:接收数据 — 真正开始发挥作用 1
2
3
import java.util.Scanner ; //导包的动作必须出现在类定义的上面
Scanner sc = new Scanner ( System . in ); //sc是变量名可以变,其余都不能变
int i = sc . nextInt (); //只有i可以变
IDEA的项目结构
IDEA的项目和模块操作
IDEA中类的相关操作
IDEA中类的相关操作
IDEA中项目相关操作
IDEA一些快捷键:
ctrl+p 查看方法参数
alt+insert 快速构造
运算符:对字面量或者变量进行操作的符号。
表达式:用运算符把字面量或者变量连接起来,符合java语法的式子就可以称为表达式。
算数运算符 加减乘除取模
”+“操作的三种情况
自增自减运算符
赋值运算符
=
+=
-=
*=
/=
%=
==*=这些底层隐藏了一个强制类型转换==
关系运算符
==关系运算符结果都是Boolean类型==
逻辑运算符
与 &
或 |
异或 ^
非 !
短路逻辑运算符 ==提升效率==
三元运算符
其他运算符
逻辑与 & 逻辑或 | 左移 « 右移 » 高位补0/1 无符号右移 »> 高位补0 顺序结构语句是Java程序默认的执行流程,按照代码的先后顺序,从上到下依次执行。
分支结构包含了两种语句,一个是if,一个是switch。
if语句
1
2
3
4
if ( 关系表达式 ) {
语句体 ;
}
//注意点:如果对一个布尔类型的变量进行判断,不要用==号,直接把变量放入小括号即可。
1
2
3
4
5
if ( 关系表达式 ) {
语句体1 ;
} else {
语句体2 ;
}
1
2
3
4
5
6
7
8
9
10
//一般用于范围的判断
if ( 关系表达式 ) {
语句体1 ;
} else if {
语句体2 ;
}
...
else {
语句体n + 1 ;
}
switch语句
switch语句格式
1
2
3
4
5
6
7
8
9
10
11
12
13
//有限的数据列举出来
switch ( 表达式 ) {
case 值1 :
语句体1 ;
break ;
case 值2 :
语句体2 ;
break ;
...;
default :
语句体n + 1 ;
break ;
}
JDK12新特性
1
2
3
4
5
6
7
8
switch ( number ) {
case 1 -> {
System . out . println ( "一" );
}
default -> {
System . out . println ( "无" );
}
}
利用case穿透,case 1,2,3等方法简化代码。
循环分为3类,分别是for,while和do…while
1
2
3
for ( 初始化语句 ; 条件判断语句 ; 条件控制语句 ) {
循环体语句 ;
}
1
2
3
4
5
初始化语句 ;
while ( 条件判断语句 ) {
循环体语句 ;
条件控制语句 ;
}
1
2
3
4
5
初始化语句 ;
do {
循环体语句 ;
条件控制语句 ;
} while ( 条件判断语句 )
数组指的是一种容器,可以用来存储同种数据类型的多个值。
数组容器在存储数据的时候,需要结合隐式转换来考虑。 例如:int类型的数据容器(byte short int) 定义格式一:
数据类型[] 数组名
示例:int [] array
定义格式二:
数据类型 数组名[]
示例:int array[]
数组的初试化:就是在内存中,为数据容器开辟空间,并将数据存入数据容器的过程。
完整格式:
数据类型[] 数组名 = new 数据类型[] {元素1,元素2,…,元素n}
示例:int[] array = new int[] {11,22,33}
简写:int[] array = {11,22,33}
地址值的格式含义:
距离:[D@776ec8df
[表示一个数组
D表示数组里面的元素是double类型
@表示间隔符号
776ec8df:数组的真正地址值
数组的元素访问
格式:数组名[索引];
数组遍历:将数组的所有内容取出来,取出来之后可以进行其他操作。
1
2
3
4
for ( int i = 0 ; i < arr , length ; i ++ ) {
遍历操作 ;
}
//idea快捷方式 数组名.fori
动态初始化:初试化时只指定数组长度,由系统为数组分配初始值。
格式:
数据类型[] 数组名 = new 数据类型[数组长度]
示例:int[] arr = new int[3]
//创建的时候由我们指定数组的长度,由虚拟机给出默认的初始化值。
数组默认初始化的规律:
整数类型默认初始化值为0
小数类型默认初始化值为0.0
字符类型默认初始化值为/u0000 即空格
布尔类型,默认初始化值为false
引用数据类型,默认初始化值为null 除四类八种以外都是引用数据类型。
动态初始化和静态初始化的区别
动态初始化:手动指定数组长度,由系统给出默认初始化值。
静态初始化:手动指定数组元素,系统会根据元素个数,计算出数组的长度。
java在计算中内存分配
java内存分配
JDK8开始,取消方法区,新增元空间。把原来方法区的多种功能进行拆分,有的功能放到了堆中,有的功能放到了元空间中。
栈 方法运行时使用的内存,比如main方法运行,进入方法栈中执行。 堆 存储对象或者数组,new创建的都存储在堆内存。 方法区 存储可以运行的class文件 本地方法栈 JVM在使用操作系统的功能的时候使用,与开发无关 寄存器 给CPU使用,与开发无关 java代码内存
java数组内存
当我们需要把数据分组管理的时候,就需要用到二维数组。
二维数组的初始化:
1
2
格式 :
数据类型 [][] 数组名 = new 数据类型 [][] {{ 元素1 , 元素2 } , { 元素a , 元素b }}
1
2
3
4
格式 :
数据类型 [][] 数组名 = new 数据类型 [ m ][ n ] ;
//m表示二维数组可以存放多少个一维数组
//n表示每一个一维数组可以存放多少个元素
二维数组的内存图
Java二维数组内存图
方法(method)是程序中最小的执行单元。
方法定义:把一些代码打包在一起,该过程称之为方法定义。
方法调用:方法定义后不是直接运行的,需要手动调用才能执行,该过程称之为方法调用。
1
2
3
4
5
6
7
8
9
10
11
12
方法定义格式 :
public static void 方法名 () {
方法体 ; //就是打包起来的代码
}
示例 :
public static void playgame () {
七个打印语句 ;
}
方法调用 :
方法名 ();
示例 :
playGame ();
1
2
3
4
5
6
7
8
9
10
11
12
方法定义格式 :
public static void 方法名 ( 参数1 , 参数2 ) {
方法体 ; //就是打包起来的代码
}
示例 :
public static void playgame () {
七个打印语句 ;
}
方法调用 :
方法名 ( 参数 );
示例 :
playGame ( 变量 );
1
2
3
4
5
6
7
8
9
10
方法定义格式 :
public static 返回值类型 方法名 ( 参数1 , 参数2 ) {
方法体 ; //就是打包起来的代码
return 返回值 ;
}
示例 :
public static int getSum ( int a , int b ) {
int c = a + b ;
return c ;
}
什么是方法的重载?
同一个类中,定义了多个同名的方法,这些同名的方法具有相同的功能。 每个方法具有不同的参数类型或参数个数,这些同名的方法,就构成了重载关系。 即同一个类中,方法名相同,参数不同的方法。与返回值无关。
参数不同可以分为:个数不同,类型不同,顺序不同。
java虚拟机会通过参数的不同来区分同名的方法。
输出语句
1
2
3
System . out . println ( "abc" ); //先打印再换行
System . out . print ( "abc" ); //只打印不换行
System . out . println (); //不打印,只换行
Java调用的基本内存原理
基本数据类型:四类八种。整数、浮点、布尔、字符。
基本数据类型中,变量中存储的是真实的数据。
基本数据类型数据值存储在自己的空间中,赋值给其他变量也是赋的真实的值。
引用数据类型:除了基本数据类型都是引用数据类型。
引用数据类型数据值存储在其他空间中,自己空间中存储的是地址值。
引用数据类型
方法的值传递
Java方法的值传递
传递基本数据类型时,传递的是真实的数据,形参的改变,不影响实际参数的值。
类是对象共同特征的描述。
对象是真实存在的具体东西。
在java中,必须先设计类,才能获得对象。
1
2
3
4
5
6
7
public class 类名 {
1 . 成员变量 ;
2 . 成员方法 ;
3 . 构造器 ;
4 . 代码块 ;
5 , 内部类 ;
}
如何得到类的对象
类名 对象名 = new 类名();
Phone p = new Phone();
如何使用对象
访问属性:对象.成员变量 访问行为:对象名.方法名(…) 补充事项
用来描述一类事物的类,专业叫做:javabean类。在javabean类中,是不写main方法的。 编写main方法的类,叫做测试类。我们可以在测试类中创建javabean类的对象并进行赋值调用。 封装告诉我们如何正确设计对象的属性和方法。
封装重要原则:对象代表什么,就得封装对应的数据,并提供数据对应的行为。
private关键字
是一个权限修饰符 可以修饰成员(成员变量和成员方法) 被private修饰的成员只能在本类中才能访问 成员变量和局部变量
变量定义在方法里面则是局部变量,变量定义再方法外面、类的里面成为成员变量。
当成员变量与局部变量重名时,采用就近原则 。
若想使用成员变量的同名关键字变量,则需要使用this关键字。
构造方法也叫构造器、构造函数。
作用:再创建对象的时候给成员变量进行初始化。
构造方法的格式
1
2
3
4
5
public class Student () {
修饰符 类名 ( 参数 ) {
方法体 ;
}
}
构造方法的特点
方法名与类名相同,大小写也要一致 没有返回值类型,连void也没有 没有具体的返回值(不能由return带回结果数据) 注意事项
构造方法的定义
创建对象的时候由虚拟机调用,不能手动调用构造方法 每创建一次对象,就会调用一次构造方法 如果没有写任何构造方法,那么虚拟机会给我们加一个空参构造方法 构造方法的重载
带参构造方法和无参数构造方法,两种方法名相同但参数不同,这叫构造方法的重载。 推荐使用方式
无论是否使用,都手动书写无参数构造方法,和带全部参数的构造方法 注意点
创造对象的时候,虚拟机会自动调用构造方法,作用是给成员变量进行初始化 标准的javabean符合以下标准
类名需要见名知意 成员变量使用private修饰 至少提供两个构造方法无参构造方法 带全部参数的构造方法 成员方法提供每一个成员变量对应是setXxx()/getXxx() 如果还有其他行为,也需要写上 ==IDEA生成javabean快捷键:alt + insert==
java内存图
Java内存图
一个对象的内存图
当执行student s = new Student(),内存里会执行以下几件事务。
加载class文件,将student类的字节码文件加载到内存 申明局部变量,对s进行申明 在堆内存中开辟一个空间,new关键字开辟空间 默认初始化 显示初始化 构造方法初始化 将堆内存中的地址赋值给左边的局部变量 一个对象的内存图
两个对象的内存图
Java两个对象的内存图
两个引用指向同一个对象
两个引用指向同一个对象
this的作用:区分局部变量和成员变量。
this的本质:所在方法调用者的地址值。
java_this的内存原理
成员变量:类中方法外的变量
局部变量:方法中的变量
成员变量和局部变量的区别
API(Application Programming Interface):应用程序编程接口。
简单理解,API就是别人已经写好的东西,我们不需要自己编写,直接使用即可。
Java API:指的就是JDK中提供的各种功能的Java类。
java.lang.String 类代表字符串,Java程序中所有字符串文字都为此类的对象。
==注意:字符串的内容是不会改变的,它的对象在创建后不能被更改。==
创建String对象的两种方式
1
2
3
4
public String (); //创建空白字符串
public String ( String orginal ); //根据传入的字符串创建字符串对象
public String ( char [] chs ); //根据字符数组,创建字符串对象
public String ( byte [] chs ); //根据字节数组,创建字符串对象
第一种方法内存原理:
String内存原理
当使用双引号直接赋值,系统会检查该字符串在串池中是否存在。
若不存在,就创建新的字符串。
若存在,就直接复用。
第二种方法内存原理:
new对象内存
Java中String类的常见方法:
比较==号比较原理:基本数据类型比数据值、引用数据类型比地址值 boolean equals方法 boolean equalsIgnoreCase方法 忽略大小写比较 遍历public char charAt(int index):根据索引返回字符 public int length():返回此字符串的长度 数组的长度:数组名.length 属性 字符串的长度:字符串对象.length() 方法 截取String substring(int beginIndex, int endIndex) 左闭右开 String substring(int beginIndex) 截取到末尾 替换String replace(旧值, 新值) 替换 为什么学习StringBuilder?
StringBuilder可以看成是一个容器,创建之后里面的内容是可变的。
StringBuilder构造方法
1
2
3
4
public StringBuilder (); //创建一个空白可变的字符串对象,不含有任何内容
public StringBuilder ( String str ); //根据字符串的内容来创建可变字符串对象
//StringBuilder是java已经写好的类,java底层对他进行了一些特殊处理
//打印对象不是地址值而是属性值
StringBuilder常用方法
1
2
3
4
public StringBuilder append ( 任意类型 ); //添加数据返回对象本身
public StringBuilder reverse (); //反转容器内容
public int length (); //返回长度
public String toString (); //通过toString就可以实现把StringBuilder转为String
StringJoiner和StringBuilder一样,也可以看成一个容器,创建之后里面的内容是可变的。 作用:提高字符串的操作效率,而且代码编写特别简洁。 ==JDK8出现== StringJoiner构造方法
1
2
public StringJoiner ( 间隔符号 ); //创建一个StringJoiner对象,指定拼接的间隔符号
public StringJoiner ( 间隔符号 , 开始符号 , 结束符号 ); //指定拼接的间隔符号,开始符号,结束符号
StringBuilder成员方法
1
2
3
public StringJoiner add ( 添加的内容 ); //添加数据并返回对象本身
public int length (); //返回长度
public String toString (); //返回一个字符串
字符串拼接的底层原理:
情况1:拼接的时候没有变量,都是字符串。此时触发字符串优化机制,在编译的时候就是最终的结果了。 情况2:有变量。 早期内存原理
java_字符串拼接
==虽然使用了StringBuilder,但是效率低的原因:多次创建StringBuilder==
字符串拼接
字符串拼接
StringBuilder源码分析:
默认创建一个长度为16的字节数组 添加的内容长度小于16,直接存 添加的内容大于16会扩容(原来的容量*2 + 2) 如果扩容之后还不够,以实际的长度为准 修改字符串的内容套路
substring 变成字符数组.toCharArray 集合和数组的对比
长度 数组长度固定,集合长度可变 存储类型 数组可以存储基本、引用数据类型,集合可以存引用数据类型,基本数据类型需要包装成类。 创建集合
1
2
3
4
5
6
//创建集合的对象
//泛型:限定集合中存储的数据类型
ArrayList < String > list = new ArrayList < String > ();
//JDK7:
//ArrayList是java已经写好的类,打印对象不少地址值,而是地址中内容
ArrayList < String > list = new ArrayList <> ();
ArrayList成员方法
1
2
3
4
5
6
boolean add ( E e ); //添加元素,返回值表示成功与否
boolean remove ( E e ); //删除指定元素
E remove ( int index ); //删除指定元素,返回被删除元素
E set ( int index , E e ); //修改指定索引下标的元素
E get ( int index ); //获取指定索引的元素
int size (); //集合长度
基本数据类型对应的包装类
byte Byte
short Short
char Character
int Integer
long Long
float Float
double Double
boolean Boolean
static表示静态,是java中的一个修饰符,可以修饰成员方法,成员变量。
被static修饰的成员变量,叫做静态变量。
特点
被该类所有对象共享 不属于对象,属于类 静态变量是随着类的加载而加载的,优于对象出现的 调用方式
static内存图
static内存图
被static修饰的成员方法,叫做静态方法。
特点:
多用在测试类和工具类中 javabean类中很少会用 调用方式:
static的注意事项
静态方法只能访问静态变量和静态方法 非静态方法可以访问静态变量和静态方法,也可以访问非静态的成员变量和成员方法 静态方法中没有this关键字 非静态的与对象相关,静态共享与某一个对象无关。
静态方法不能调用实例变量
重新认识main方法
public:被jvm调用,访问权限足够大 static:被jvm调用,不能创建对象,直接类名访问。因为main方法是静态的,所以测试类中的其他方法也需要是静态的。 void:被jvm调用,不需要给jvm返回值。 main:一个通用的名称,虽然不是关键字,但是被jvm识别。 String[] args:以前用于接收键盘录入数据的,现在没用。 java提供一个关键字extends,用这个关键字,我们可以让一个类和另一个类建立继承关系。 public class Student extends Person {}
Student称为子类(派生类),Person称为父类(基类)。 使用继承的好处
可以把多个子类中重复的代码提取到父类中,提高代码的复用性。 子类可以在父类的基础上,增加其他的功能,使子类更强大。 什么时候用到继承?
当类与类之间,存在相同的内容,并满足子类是父类中的一种,就可以考虑用继承的来优化代码。
继承的特点
Java只支持单继承,不支持多继承,但支持多层继承。
单继承:一个子类只能继承一个父类。 不支持多继承:子类不能同时继承多个父类 多层继承:子类A继承父类B,父类B可以继承父类C B是A的直接父类,C是A的间接父类 ==每一个类都直接或者间接继承于Object==
子类只能访问父类中非私有的成员。
子类能继承父类中的哪些内容?
两个误区:
误区1:父类私有的东西,子类就无法继承 误区2:父类中非私有的成员,就被子类继承下来了 子类继承父类
==只有父类中的虚方法才能被子类继承==
Java继承内存图
Java方法继承
继承中成员变量和成员方法的访问特点
继承中成员变量的访问特点:就近原则 。
this关键字 本类中成员变量 super关键字 父类中成员变量 继承中成员方法的访问特点:就近原则 。
方法的重写
当父类的方法不能满足子类现在的需求时,需要进行方法重写。
书写格式:在继承体系中,子类出现了和父类中一模一样的方法申明,我们就称子类这个方法是重写的方法。
@Override重写注释
@Override是放在重写后的方法上,校验子类重写时语法是否正确。 加上注解示意虚拟机这是方法重写,此时如果出现红色波浪线表示语法出现错误。 ==建议重写方法都加上@Override注解,代码安全优雅。== 方法重写的本质
方法重写的本质是子类重写的方法是覆盖了虚方法表中的方法。
Java方法重写的本质
方法重写的注意事项和要求
重写方法的名称、形参列表必须与父类中的一致。 子类重写父类方法时,访问权限子类必须大于等于父类。(空<protected<public) 子类重写父类方法时,返回值类型必须子类型小于等于父类型。 ==重写方法尽量与父类保持一致。== 只有被添加到虚方法表中的方法才能被重写。 继承中构造方法的访问特点
父类中的构造方法不会被子类继承。(假设可以继承,那么构造方法名与类名不一致) 子类中所有的构造方法默认先访问父类中的无参构造,再执行自己。原因:子类在初始化的时候,有可能会使用到父类中的数据,如果父类没有完成初始化,子类无法使用父类中的数据。 ==子类初始化之前,一定要调用父类构造方法先完成父类数据空间的初始化。== 怎么调用父类构造方法?子类构造方法的第一行语句默认都是:super(),不写也存在,且必须在第一行。 如果想调用父类有参构造,必须手动写super进行调用。 this、super使用总结
this:理解为一个变量,表示当前方法调用者的地址值。 super:代表父类存储空间。
什么是多态?
同类的对象,表现出不同形态。
多态的表现形式
父类类型 对象名称 = 子类对象;
多态的前提
多态的好处
使用父类类型作为参数,可以接收所有子类对象,体现多态的拓展性与便利。
多态调用成员的特点
变量调用:编译看左边,运行也看左边。 方法调用:编译看左边,运行看右边。编译看左边:javac编译代码的时候,会看左边的父类中有没有这个对象,如果有编译成功,如果没有编译失败。 运行看左边:java运行代码的时候,实际获取的就是左边父类中成员变量的值。 运行看右边:java运行代码的时候,实际运行的是子类里面的方法。 如何理解?
Animal a = new dog();
现在用a调用变量和方法。而a是animal类的,所以默认都会从animal这个类中去找。 成员变量:在子类的对象中,会把父类的成员变量也继承下来。具体调用谁看变量是父类还是子类。 成员方法:如果子类对方法进行了重写,那么在虚方法表中会对父类方法进行覆盖。 多态调用成员的内存图理解
Java多态调用内存原理
多态的优势
在多态形式下,右边对象可以实现解耦合,便于拓展和维护。 定义方法的时候,使用父类类型作为参数,可以接收所有子类对象,体现多态的拓展性和便利。 多态的弊端
包、final、权限修饰符、代码块
什么是包?
包就是文件夹。用来管理各种不同功能的Java类,方便后期代码维护。
包名的规则:公司域名反写 + 包的作用,需要全部英文小写,见名知意。 使用其他类的规则使用同一个包中的类时,不需要导包。 使用java.lang包中的类时,不需要导包。 其他情况都需要导包。 如果同时使用两个包中的同类名,需要使用全类名。 1
2
3
4
5
6
//方式1
com . xxx . xxx . Student
s = new com . xxx . xxx . Student ();
//方式2
import com.xxx.xxx.Student ;
Student s = new Student ();
final关键字
final关键字可以修饰三种内容:
方法:表明该方法是最终方法,不能被重写 类:表明该类是最终类,不能被继承 变量:叫做常量,只能被赋值一次 常量
在实际开发中,常量一般作为系统的配置信息,方便维护,提高可读性。
常量的命名规范:
单个单词:全部大写 多个单词:全部大写,单词之间用下划线隔开 细节:
final修饰的变量是基本类型:那么变量存储的数据值不能发生改变。 final修饰的变量是引用类型:那么变量存储的地址值不能发生改变,对象内部的可以改变。 权限修饰符
权限修饰符是用来控制一个成员能够被访问的范围的。可以修饰成员变量,方法,构造方法,内部类。
使用规则:实际开发中,一般只用private和public
成员变量私有 方法公开 ==特例:如果方法中的代码是抽取其他方法中共性代码,这个方法一般也私有。== 代码块
局部代码块:写在方法内部的大括号 构造代码块定义:写在成员位置的代码块 作用:可以把多个构造方法中重复的代码抽取出来 执行时机:在创建本类对象的时候会执行构造代码块再执行构造方法。 逐渐淘汰 静态代码块:在构造代码块前加了static关键字格式:static {} 特点:需要通过static关键字修饰,随着类的加载而加载,并且自动触发,==只执行一次==。 使用场景:在类的加载的时候,做一些数据初始化的时候使用。 抽象类和抽象方法的定义
抽象类和抽象方法的定义格式
1
public abstract 返回值类型 方法名 ( 参数列表 );
1
public abstract class 类名 {}
抽象类和抽象方法的注意事项
抽象类不能实例化 抽象类中不一定有抽象方法,有抽象方法的类一定是抽象类 可以有构造方法 抽象类的子类 接口就是一种规则,是对行为的抽象。
接口的定义和使用
接口不能实例化 接口和类之间是实现关系,通过implements关键字表示 1
public class 类名 implements 接口名 {}
接口的子类(实现类)
注意事项
1
public class 类名 implems 接口名1 , 接口名2 {}
1
public class 类名 extends 父类 implements 接口名1 , 接口名2 {}
接口中成员的特点
成员变量只能是常量 默认修饰符:public static final 构造方法:没有构造方法 成员方法只能是抽象方法 默认修饰符:public abstractJDK7以前:接口中只能定义抽象方法。 JDK8的新特性:接口中可以定义有方法体的方法。 JDK9的新特性:接口中可以定义私有方法。 接口和类之间的关系
类和类的关系:继承关系,只能单继承,不能多继承,但是可以多层继承。 类和接口的关系:实现关系,可以单实现,也可以多实现,还可以在继承一个类的同时实现多个接口。 接口和接口的关系:继承关系,可以单继承,也可以多继承。 JDK8开始接口中新增的方法
JDK7以前:接口中只能定义抽象方法。 JDK8的新特性:接口中可以定义有方法体的方法。(默认、静态)默认方法:需要使用default关键字修饰,解决接口升级的问题。 格式:public default 返回值类型 方法名(参数列表){ } 注意事项:默认方法不是抽象方法,所以不强制重写。但是如果被重写,重写的时候去掉default关键字。public可以省略,default不能省略。如果实现了多个接口,多个接口中存在相同名字的默认方法,子类就必须对该方法重写。 静态方法:格式:public static 返回值类型 方法名(参数列表){ } 静态方法只能通过接口名调用,不能通过实现类名或者对象名调用。 public可以省略,static不能省略。 JDK9的新特性:接口中可以定义私有方法。默认方法定义格式:private void show(){ }//注意没有default 静态方法定义格式:private static void method(){ } 接口的应用
接口代表规则,是行为的抽象。想让哪个类拥有一个行为,就让这个类实现对应的接口就可以了。 当一个方法的参数是接口时,可以传递接口所有实现类的对象,这种方式称之为接口多态。 适配器设计模式
设计模式(design pattern)是一套被反复使用,多数人知晓的,经过分类编目的,代码设计经验的总结。使用设计模式是为了可重用代码、让代码更容易被人理解、保证代码可靠性、程序的重用性。简单来说,设计模式就是各种套路。
适配器设计模式:解决接口与接口实现类之间的矛盾问题。
当一个接口中抽象方法过多,但是只要用其中一部分的时候,就可以适配器设计模式。 书写步骤 1
2
3
4
编写中间类xxxAdapter , 实现对应的接口 ;
对接口中的抽象方法进行空实现 ;
让真正的实现类继承中间类 , 并重写需要用的方法 ;
为了避免其他类创建适配器类的对象 , 中间的适配器类用abstract进行修饰 。
内部类就是在一个类的里面,再定义一个类。如在A类的内部定义B类,B类就称为内部类。
1
2
3
4
5
public class Outer { //外部类
public class Inner { //内部类
xxx ; //内部类的事物是外部类的一部分,内部类单独出现没有任何意义。
}
}
内部类的访问特点:
内部类可以直接访问外部类的成员,包括私有。 外部类访问内部类成员,必须创建对象。 内部类的分类
成员内部类
写在成员位置的,属于外部类的成员。 成员内部类可以被一些修饰符修饰,比如:private,默认,protected,public,static等。 在成员内部类里面,JDK16之前不能定义静态变量,JDK16开始才可以定义静态变量。 获取成员内部类对象的两种方式
方式一:在外部类中编写方法,对外提供内部类对象。(private) 1
2
3
public Inner getInstance (){
return new Inner ();
}
方式二:直接创建格式:外部类名.内部类名 对象名 = 外部类对象.内部类对象; 1
Outer . Inner oi = new Outer (). new Inner ();
成员内部类获取外部类的成员变量
没有重名直接调用外部类即可
1
2
3
4
5
6
7
8
9
10
11
12
13
public class Outer {
private int a = 10 ;
class Inner {
private int a = 20 ;
public void show () {
int a = 30 ;
System . out . println ( a ); //30
System . out . println ( this . a ); //20
//out.this获取了外部类对象的地址值
System . out . println ( Outer . this . a ); //10
}
}
}
内部类的内存图
Java内部类的内存图
静态内部类
静态内部类只能访问外部类中的静态变量和静态方法,如果想要访问非静态的需要创建对象。
创建静态内部类对象的格式:外部类名.内部类名 对象名 = new 外部类名.内部类名()
调用非静态方法的格式:先创建对象,用对象调用
调用静态方法的格式:外部类名.内部类名.方法名()
1
2
3
4
5
6
7
8
9
public class Outer { //外部类
static class Inner { //静态内部类
xxx ;
}
}
//创建静态内部类对象
Outer . Inner oi = new Outer . Inner (); //new关键字与Inner直接交互
//调用静态方法
Outer . Inner . show2 ();
局部内部类
将内部类定义在方法里面就叫做局部内部类,类似于方法里面的局部变量。
外界是无法直接使用局部内部类,需要在方法内部创建对象并使用。
该类可以直接访问外部类成员,也可以访问方法内的局部变量。
匿名内部类
匿名内部类本质上就是隐藏了名字的内部类。可以写在成员位置,也可以写在局部位置。
格式:
1
2
3
4
5
6
7
8
9
new 类名或者接口名 () { //内容包含继承/实现 -> 方法重写 -> 创建对象
重写方法 ;
};
//举例
new Inter () {
public void show () {
}
}
1
2
3
4
5
6
public class Student extends Swim {
@override
public void swim () {
xxx ;
}
}
实现过程:
把前面的class删掉,剩余的内容就变成了一个没有名字的类。 这个没有名字的类想要实现swim接口。把swim写在大括号的前面,表示这个名字的类实现了swim接口,所以需要在类中重写接口里所有的抽象方法。 根据new 类名() ;的格式完善代码。如下所示: 1
2
3
4
5
6
7
8
9
//匿名类的主体是{}之间的内容
//类实现了接口swim
//new的类的主体不是接口
new Swim () { //若是接口则为实现关系,若为类则为继承关系
@override
public void swim () {
xxx ;
}
};
使用场景:如果一个类只需要用一次,那么单独定义一个类太麻烦。此时可以采用内部类。
math类介绍
是一个帮助我们进行数学计算的工具类 私有化构造方法,所有的方法都是静态的 math类的常用方法
public static int abs(int a) 获取参数绝对值 public static double ceil(double a) 向上取整 public static double floor(double a) 向下取整 public static int round(float a) 四舍五入 public static int max(int a, int b) 获取两个int值的较大值 public static double pow(double a, double b) 返回a的b次幂 public static double random() [0.0,1.0)随机数 System类介绍
System类也是一个工具类,提供了一些与系统相关的方法。
System类的常用方法
public static void exit(int status) 中止当前的java虚拟机
状态码
0:表示当前虚拟机是正常停止。当需要把整个程序都结束的时候就调用这个方法。 非0:表示虚拟机是异常停止。 public static long currentTimeMillis() 返回当前系统的时间毫秒形式
计算机中的事件原点:1970年1月1日 00:00:00 ,c语言的生日。 由于时区的存在,我国的原点时间是1970年1月1日 08:00:00 public static void arraycopy(数据源数组,起始索引,目的地数组,起始索引,拷贝个数) 数组拷贝
如果数据源数组和目的地数组都是基本数据类型,那么两者的类型必须保持一致,否则会报错。 在拷贝的时候需要考虑数组的长度,如果超出范围会报错。 如果数据源数组和目的地数组都是引用数据类型,那么子类类型可以赋值给父类类型。 Runtime介绍
Runtime表示当前虚拟机的运行环境。
Runtime类的常用方法
public static Runtime getRuntime() 当前系统的运行环境对象 public void exit(int status) 停止虚拟机(System的exit方法底层实现就是调用Runtime的exit方法) public int availableProcessors() 获取CPU线程数 public long maxMemory() JVM能从系统中获取的内存大小(单位byte) public long totalMemory JVM已经从系统中获取的内存大小(单位byte) public long freeMemory() JVM剩余内存大小(单位byte) public Process exec(String command) 运行CMD命令 Object介绍
Object是java中的顶级父类,所有的类都直接或间接继承于object类。 Object类中的方法可以被所有子类访问,所以需要学习Object类和其中的方法。 Object的构造方法
Object的成员方法
1
2
3
4
5
6
7
8
9
10
String s = "abc" ;
StringBuilder sb = new StringBuilder ( "abc" );
System . out . println ( s . equals ( sb )); //false
System . out . println ( sb . equals ( s )); //false
/*
第一个为false原因:
String中的equals方法经过重写,重写后的逻辑为先判断是否为字符串,若是字符串才比较内部属性。如果参数不是字符串,直接返回false。
第二个为false原因:
StringBuilder没有重写equals方法,使用的是Object类中的equal方法。默认比较的是两个对象的地址值。
*/
Objects类介绍
Objects是一个工具类,提供了一些方法去完成一些功能。
Objects的成员方法
public static boolean equals(object a,object b) 先做非空判断,比较两个对象方法底层判断a是否为null,如果为null,直接返回false a不为null,那么利用a再次调用equals方法 如果a是子类,那么会调用子类中的equals方法,没有重写,比较地址值,重写了则比较属性值。 public static boolean isNull(Object obj) 判断对象是否为null,为null则返回true public static boolean nonNull 判断对象是否为null,和isNull结果相反 BigInteger
在java中,整数有四种类型:byte,short,int,long
在底层占用字节个数:byte1个字节,short2个字节,int4个字节,long8个字节
BigInteger构造方法
public BigInteger(int num, Random rnd) 获取随机大整数 范围[0,2^num - 1] public BigInteger(String val) 获取指定的大整数,字符串必须是整数,否则报错 public BigInteger(String val, int radix) 获取指定进制的大整数 public static BigInteger valueOf(long val) 静态方法获取BigInteger的对象,内部有优化提前把-16~16先创建好BigInteger的对象,如果多次获取不会创建新的 ==BigInteger对象一旦创建,内部记录的值不能发生改变。==
构造方法小结
如果BigInteger表示的数字没有超过long的范围,可以用静态方法获取。 如果BigInteger表示超过long的范围,可以使用构造方法获取。 对象一旦创建,BigInteger内部记录的值不能发生改变。 只要进行计算都会产生一个新的BigInteger对象。 BigInteger常见成员方法
public BigInteger add(BigInteger val) 加法 public BigInteger substract(BigInteger val) 减法 public BigInteger multiply(BigInteger val) 乘法 public BigInteger divide(BigInteger val) 除法,获取商 public BigInteger[] divideAndRemainder(BigInteger val) 除法,获取商和余数 public Boolean equals(Object x) 比较是否相同 public BigInteger pow(int exponent) 次幂 public BigInteger max/min(BigInteger val) 返回较大值,较小值 public int intValue(BigInteger val) 转为int类型整数,超出范围数据有误 BigInteger底层存储方式
对于计算机而,没有数据类型这个概念,都是0和1。 数据类型是编程语言自己规定的。 包含signum和mag两个属性,将大数字拆开存储。 BigDecimal介绍
BigDecimal构造方法
public BigDecimal(double val)不精确,不建议使用 public BigDecimal(string val) public static BigDecimal valueOf(double val) 静态方法 注意事项
如果表示的数字不大,没有超出double的表示范围,建议使用静态方法。 如果表示的数字比较大,超出了double的表示范围,建议使用构造方法。 如果传递的是0-10之间的整数,那么方法会返回已经创建好的对象,不会重新new。 Bigdecimal的方法
public Bigdecimal add(BigDecimal val) 加法 public Bigdecimal substract(BigDecimal val) 减法 public Bigdecimal multiply(BigDecimal val) 乘法 public Bigdecimal divide(BigDecimal val) 除法,除不尽会报错 public Bigdecimal divide(BigDecimal val, 精确几位, 舍入模式) 除法 BigDecimal底层存储方式
拆成字符,存储字符对应的ascii码数值。
正则表达式作用
正则表达式可以校验字符串是否满足一定的规则,用来检验数据格式的合法性。 在一段文本中查找满足要求的内容。 正则表达式
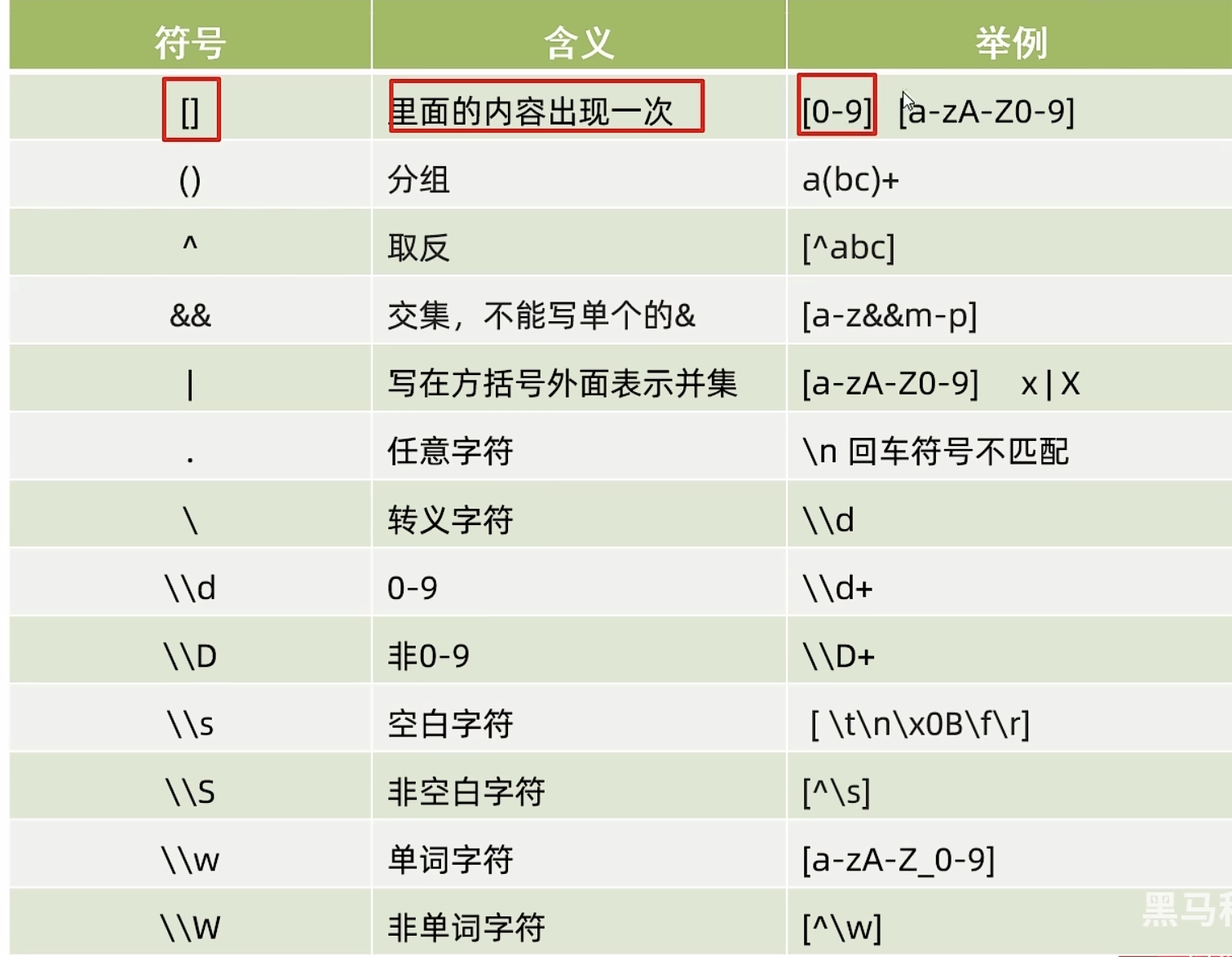
字符类:
[]表示一个范围
[abc] 只能是a,b或c
[^abc]除了abc之外的任何字符
[a-zA-Z]a到z或者A到Z
[a-d[m-p]]a到d或者m到p,和上面一样
[a-z&&[def]]a到z和def的交集。为d,e,f ==如果只写了一个&,那么单单表示一个&符号而已==
[a-z&&[ ^bc ] ]a-z和非bc的交集。等同于[ad-z]
[a-z&&[ ^m-p]]a到z和除了m到p的交集。等同于[a-lq-z]
预定义字符:
. 任意字符
\d 一个数字[0-9]
\D 非数字[ ^ 0 - 9]
\s 一个空白字符[\t \b \x0B \f \r ]
\S 非空白字符[ ^ \s]
\w [a-zA-Z_0-9]英文字母下划线
\W[ ^\w] 一个非单词字符
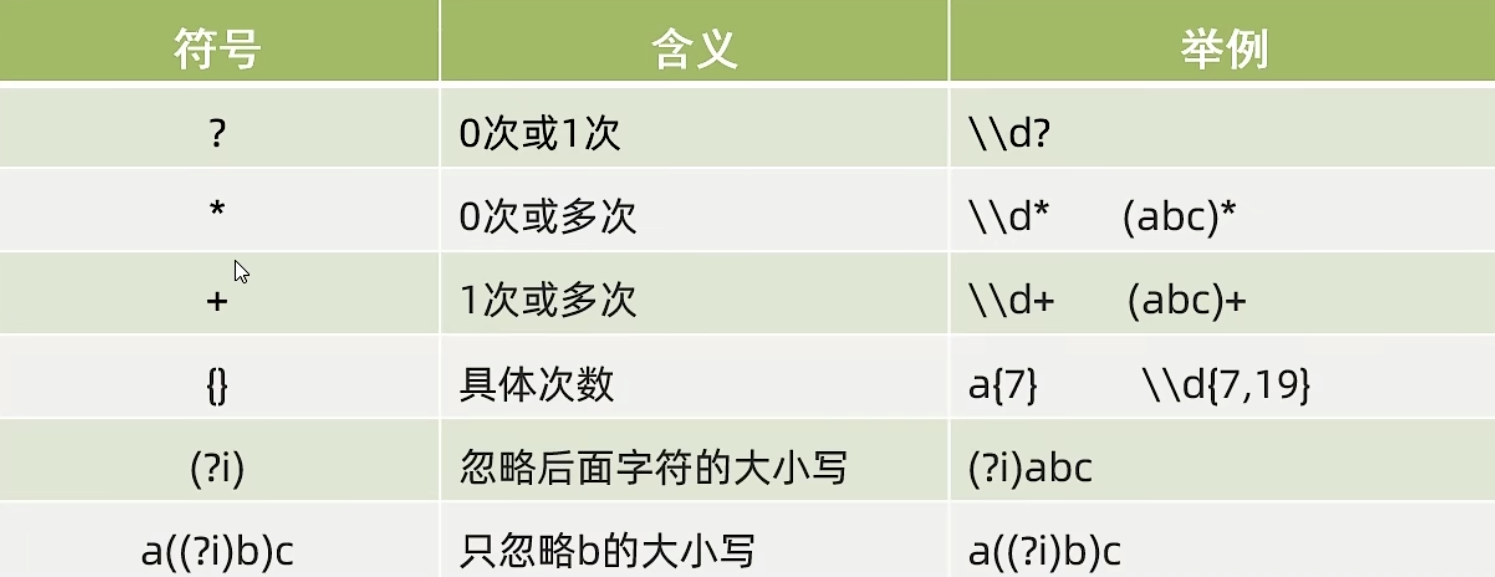
数量词
X? X,一次或0次
X*,X,零次或者多次
X+,X,一次或者多次
X{n} X,正好n次
X{n,} X,至少n次
X{n,m} X,至少n但不超过m次
正则表达式爬虫
regex下的两个类
Pattern:表示正则表达式 Matcher:文本匹配器,作用按照正则表达式的规则去读取字符串,从头开始读取。在大串中去找符合规则的子串。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import java.util.regex.Pattern ;
import java.util.regex.Matcher ;
//1.获取正则表达式的对象
Pattern p = pattern . compile ( "正则表达式" );
//m 文本适配器的对象
//p规则
//m要在str中寻找符合p规则的小串
//2.获取文本匹配器的对象
Matcher m = p . matcher ( str );
//3.利用循环获取
while ( m . find ()) {
string s = m . group ();
System . out . println ( s );
}
/*详细过程说明
//拿着文本适配器从头开始读取,寻找是否有满足规则的子串
//如果没有返回false
//有则返回true,在底层记录起始索引和结束索引+1
boolean b = m.find();
//方法会根据find方法记录的索引进行字符串的截取
//substring
String s1 = m.group();
System.out.println(s1);
//第二次调用find的时候,会继续读取后面的内容
b = m.find();
String s2 = m.group();
System.out.println(s2);
*/
网络爬虫举例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class RegexDemo {
public static void main ( String [] args ) {
//创建url对象
URL url = new URL ( "url" );
//连接网址
URLConnection conn = url . openConnection ();
//创建一个对象读取网络中的数据
BufferedReader br = new BufferedReader ( new InputStreamReader ( conn . getInputStream ()));
String line ;
//获取正则表达式对象pattern
String regex = "[1-9]\\d{17}" ;
Pattern pattern = Pattern . compile ( regex );
while (( line = br . readLine ()) != null ) {
Matcher matcher = pattern . matcher ( line );
while ( matcher . find ()) {
System . out . println ( matcher . group ());
}
}
br . close ();
}
}
带条件爬取
1
2
3
4
5
6
7
8
//需求1:爬取版本号为8,11,17的java版本,但是只要java,不显示版本号。
//?理解为前面的数据java,=表示java后面跟随的数据,但在获取的时候,只获取前半部分。
String regex = "java(?=8|11|17)" ;
//需求2:爬取版本号为8,11,17的java版本,正确爬取结果为:java8 java11 java 17
String regex = "java(?:8|11|17)" ;
String regex = "java(8|11|17)" ;
//需求2:爬取除了版本号为8,11,17的java版本
String regex = "java(?!8|11|17)" ;
贪婪爬取和非贪婪爬取
贪婪爬取:在爬取数据的时候尽可能的多获取数据。
非贪婪爬取:在爬取数据的时候尽可能的少获取数据。
java中,默认就是贪婪爬取。如果在数量词+ *后面加上问号,那么此时就是非贪婪爬取。
1
2
3
4
5
String = "abbbbbbbbbbbabaaaaaaaaaaaaaaaaaaaaaaaaaaa" ;
//需求1:按照ab+的方式爬取ab,b尽可能多获取
String regex = "ab+" ;
//需求2:按照ab+的方式爬取ab,b尽可能少获取
String regex = "ab+?" ;
正则表达式在字符串方法中的使用
public String[] matches(String regex) 判断字符串是否满足正则表达式的规则 public String replaceAll(String regex, String newStr) 按照正则表达式的规则进行替换 public String[] split(String regex) 按照正则表达式的规则切割字符串 1
2
3
4
5
6
String s = "字符串" ;
//需求1:替换字符串
//底层实现:Pattern.compile(regex).matcher(this).replaceAll(replacement)
String result = s . replaceAll ( regex , replacement );
//需求2:把字符串中的三个姓名切割出来
String [] result = s . split ( regex );
正则表达式的分组规则
规则1:从1开始,连续不间断。 规则2:以左括号为基准,最左边的是第一组,其次为第二组,以此类推。 捕获分组
捕获分组就是把这一组的数据捕获出来,再用一次。
正则表达式内部使用:\ \组号
正则表达式外部使用:$
1
2
3
4
5
6
7
8
9
10
11
//需求1:判断一个字符串的开始字符和结束字符是否一致?只考虑一个字符。
//举例:a123a b456b 17981 &abc&
// \\组号,表示把第x组的内容再出来用一次
String regex1 = "(.).+\\1" ;
//需求2:判断一个字符串的开始部分和结束部分是否一致?可以多个字符。
//举例:abc123abc 123789123
String regex2 = "(.+).+\\1" ;
//需求3:判断一个字符串的开始部分和结束部分是否一致?开始部分内部每个字符也要一致。
//举例:aaa123aaa bbb456bbb 111789111
//(,)\\2* 保证开始部分一致
String regex2 = "((.)\\2*).+\\1"
非捕获分组
分组之后不需要再用本组数据,仅仅是把数据括起来。这种用法不占用组号。
(?:)(?!)(?=)都是非捕获分组。
JDK前时间相关类
Date 时间 SimpleDateFormat 格式化时间 Calendar 日历 Date时间类
Date类是一个JDK写好的JavaBean类,用来描述时间,精确到毫秒。
利用空参构造创建的对象,默认表示系统当前时间。
利用有参构造创建的对象,表示指定的时间。
1
2
3
4
5
6
7
8
9
10
11
12
//1.创建一个对象表示时间
Date d1 = new Date ();
System . out , println ( d1 );
//2.创建一个对象表示指定的时间
Date d2 = new Date ( 0L ); //表示从时间原点开始,过了0毫秒的时间。
System . out . println ( d2 );
//3.setTime修改时间
d2 . setTime ( 1000L ); //表示从时间原点开始,过了1000毫秒时间
System . out . println ( d2 );
//4.getTime获取当前时间毫秒值
long time = d2 . getTime (); //1000
System . out . println ( time );
SimpleDateFormat类
作用:
格式化:把时间变成易于阅读的形式。 解析:把字符串表示的时间变成Date对象。 构造方法:
public SimpleDateFormat() 构造一个SimpleDateFormat,使用默认格式。 public SimpleDateFormat(String pattern) 构造一个SimpleDateFormat,使用指定格式。 常用方法:
public final String format(Date date) 格式化(日期对象 -> 字符串) public Date parse(String source) 解析(字符串->日期对象) 1
2
3
4
5
6
7
//1.利用空参构造创建SimpleDateFormat对象,默认格式
SimpleDateFormate sdf1 = new SimpleDateFormat ();
Date d = new Data ( 0L );
String str1 = sdf1 . format ( d );
//1.利用带参构造创建SimpleDateFormat对象,指定格式
SimpleDateFormate sdf2 = new SimpleDateFormat ( "yyyy年MM月dd日 HH:mm:ss" );
String str2 = sdf2 . format ( d );
1
2
3
4
5
6
7
8
//1.定义一个字符串表示时间
String str = "2023-11-11 11:11:11" ;
//2.利用空参构造创建SimpleDateFormat对象
//创建对象的格式要和字符串的格式完全一致
SimpleDateFormate sdf = new SimpleDateFormat ( "yyyy-MM-dd HH:mm:ss" );
Date date = sdf . parse ( str ); //ctrl + alt + v自动生成左边
//3.打印结果
System . out . println ( date );
Calendar类
Calendar代表了系统当前时间的日历对象,可以单独修改、获取时间中的年,月,日。 Calendar是一个抽象类,不能直接创建对象。 获取Calendar日历类对象的方法
public static Calendar getInstance() 获取当前时间的日历对象
Calendar常用方法
public final Date getTime() 获取日期对象 public final setTime(Date date) 给日历设置日期对象 public long getTimeInMillis() 拿到时间毫秒值 public void setTimeInMillis(long millis) 设置时间毫秒值 public int get(int field) 取日历中某个字段信息 public void set(int field, int value) 修改日历的某个字段信息 public void add(int field, int amount) 为某个字段增加、减少指定的值 1
2
3
4
5
6
7
8
9
10
11
12
//1.获取日历对象
//Calendar是一个抽象类,不能直接new,而是通过一个静态方法获取子类对象
//底层原理:根据系统的不同时区来获取不同的日历对象。会把事件中的纪元、年月日等等放入一个数组当中。
Calendar c = Calendar . getInstance ();
//2.修改日历代表的时间
//月份范围是0-11.星期日是一周中的第一天
Date d = new Date ( 0L );
c . setTime ( d );
//0:纪元 1:年 2:月 3:一年中的第几周 4:一个月中的第几周 5:一个月中的第几天
//java在calendar类中,把索引对应的数字都定义成常量
int year = c . get ( 1 );
int year = c . get ( Calendar . YEAR );
JDK8新增时间类
原因
Java新增时间类原因
JDK8时间类
JDK8时间类
Zoneid时区常用方法
static Set getAvailableZoneIds() 获取java中支持的所有时区 static ZoneId systemDefault() 获取系统默认时区 static ZoneId of(String ZoneId) 获取一个指定时区 1
2
3
4
5
6
//1.获取所有的时区名称
Set < String > availableZoneIds = ZoneId . getAvailableZoneIds ();
//2.获取当前系统的默认时区
ZoneId ZoneId = ZoneId . systemDefault ();
//3.获取指定的时区
ZoneId ZoneId1 = ZoneId . of ( "Asia/Shanghai" );
Instant时间戳
static Instant now() 获取当前的Instant时间(标准时间) static Instant ofxxx(long epochMilli) 根据(秒/毫秒/纳秒)获取Instant对象 ZonedDateTime atZone(ZoneId zone) 指定时区 boolean isXXX(Instant otherInstant) 判断系列的方法 Instant minusXxx(long millisToSubstract) 减少时间系列的方法 Instant plusXxx(long millisToSubtract) 增加时间系列的方法 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
//1.获取当前时间的Instant对象
Instant now = Instant . now ();
//2.根据(秒/毫秒/纳秒)获取Instant对象
Instant instant1 = Instant . ofEpochMilli ( 0L );
Instant instant2 = Instant . ofEpochSecond ( 1L );
Instant instant3 = Instant . ofEpochSecond ( 1L , 1000000000L ); //第一个参数单位秒,第二个参数为纳秒
//3.指定时区
ZonedDateTime time = Instant . now (). atZone ( ZoneId . of ( "Asia/Shanghai" ));
//4.isXxx 判断
//isBefore:判断调用者代表的时间是否在参数表示时间的前面
Instant instant4 = Instant . ofEpochMilli ( 0L );
Instant instant5 = Instant . ofEpochMilli ( 1000L );
boolean isBefore = Instant4 . isBefore ( instant5 );
//5.减少时间系列的方法
Instant instant6 = Instant . ofEpochMilli ( 10000L );
Instant instant7 = Instant6 . minusSecond ( 1 );
ZonedDateTime带时区的时间
static ZonedDateTime now() 获取当前时间的ZoneDateTime对象 static ZonedDateTime ofXxx() 获取指定时间的ZonedDateTime对象 ZonedDateTime withXxx(时间) 修改时间系列的方法 ZonedDateTime minusXxx(时间) 减小时间系列的方法 ZonedDateTime plusXxx(时间) 增加时间系列的方法 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
//1.获取当前时间对象(带时区)
ZonedDateTime now = ZonedDateTime . now ();
//2.获取指定的时间对象
ZonedDateTime time1 = ZonedDateTime . of ( 2023 , 10 , 1 , 11 , 12 , 12 , 0 , ZoneId . of ( "Asia/Shanghai" ));
//通过Instant+时区的方式指定获取时间对象
Instant instant = Instant . ofEpochMilli ( 0L );
ZoneId zoneId = ZoneId . of ( "Asia/Shanghai" );
ZonedDateTime time2 = ZonedDateTime . ofInstant ( instant , ZoneId );
//3.withXxx修改时间系列的方法
ZonedDateTime time3 = time2 . withYear ( 2000 ); //修改年份为2000
//4.减少时间
ZonedDateTime time4 = time2 . minusYear ( 1 );
//5.增加时间
ZonedDateTime time5 = time2 . plusYear ( 1 );
//JDK8新增的时间对象是不可变的,如果修改时间,调用者是不会发生改变而是产生一个新的时间。
DateTimeFormatter时间格式化类
static DateTimeFormatter ofPattern(格式) 获取格式对象 String format(时间对象) 按照指定方式格式化 1
2
3
4
5
6
//获取时间对象
ZonedDateTime time = Instant . now (). atZone ( ZoneId . of ( "Asia/Shanghai" ));
//解析/格式化器
DateTimeFormatter dtf1 = DateTimeFormatter . ofPattern ( "yyyy-MM-dd HH;mm;ss EE a" );
//格式化
System . out . println ( dft1 . format ( time ));
日历类LocalDate、LocalTime、LocalDateTime
static XXX now() 获取当前时间的对象 static XXX of(…) 获取指定的时间对象 get开头的方法 获取日历中的年月日时分秒等信息 isBefore、isAfter 比较两个LocalTime with开头的方法 修改时间系列的方法 minus开头的方法 减少时间系列的方法 plus开头的方法 增加时间系列的方法 LocalDateTime转LocalDate、LocalTimepublic LocalDate toLocateDate() public LocalTime toLocateTime() 1
2
3
4
5
6
7
8
9
10
11
12
//1.获取当前的日历对象
LocalDate nowDate = LocalDate . now ();
//2.获取指定的时间的日历对象
LocalDate idDate = LocalDate . of ( 2023 , 1 , 1 );
//3,get系列方法获取日历中的每一个属性值
int year = idDate . getYear ();
//is开头表示判断
idDate . isBefore ( idDate );
//with开头表示修改 minus表示减少 plus表示增加
LocalDate dateTime = idDate . withYear ( 2000 );
LocalDate dateTime = idDate . plusYear ( 1 );
LocalDate dateTime = idDate . minusYear ( 1 );
工具类Duration、Period、ChronoUnit
Duration 计算两个时间的时间间隔 Period 计算两个日期的时间间隔 ChronoUnit 计算两个日期的间隔 1
2
3
Period period = Period . between ( birthDate , today ); //第二个参数减第一个参数
Duration duration = Duration . between ( birthDate , today );
ChronoUnit . YEARS . between ( birthDate , today ); //相差多少年
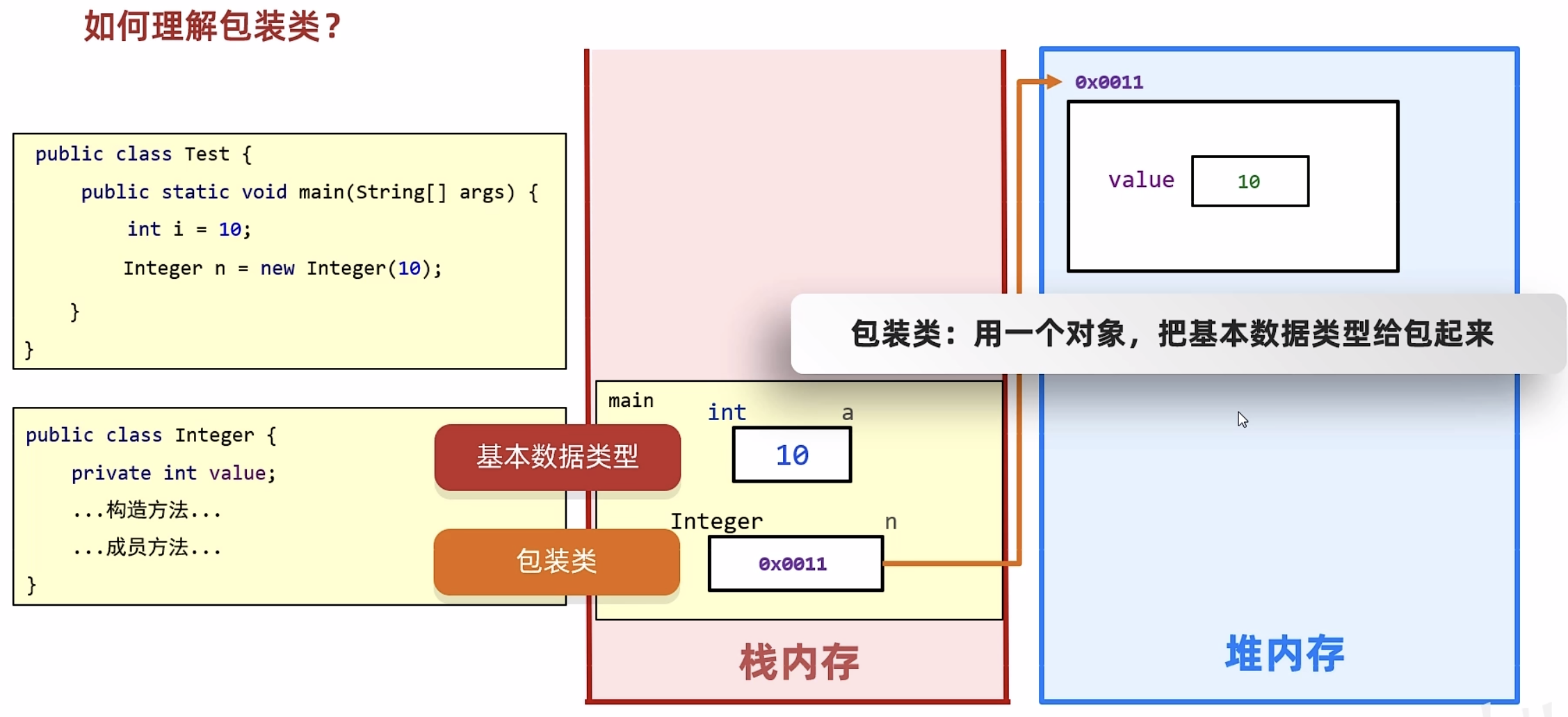
什么是包装类
包装类:基本数据类型对应的引用数据类型。
包装类
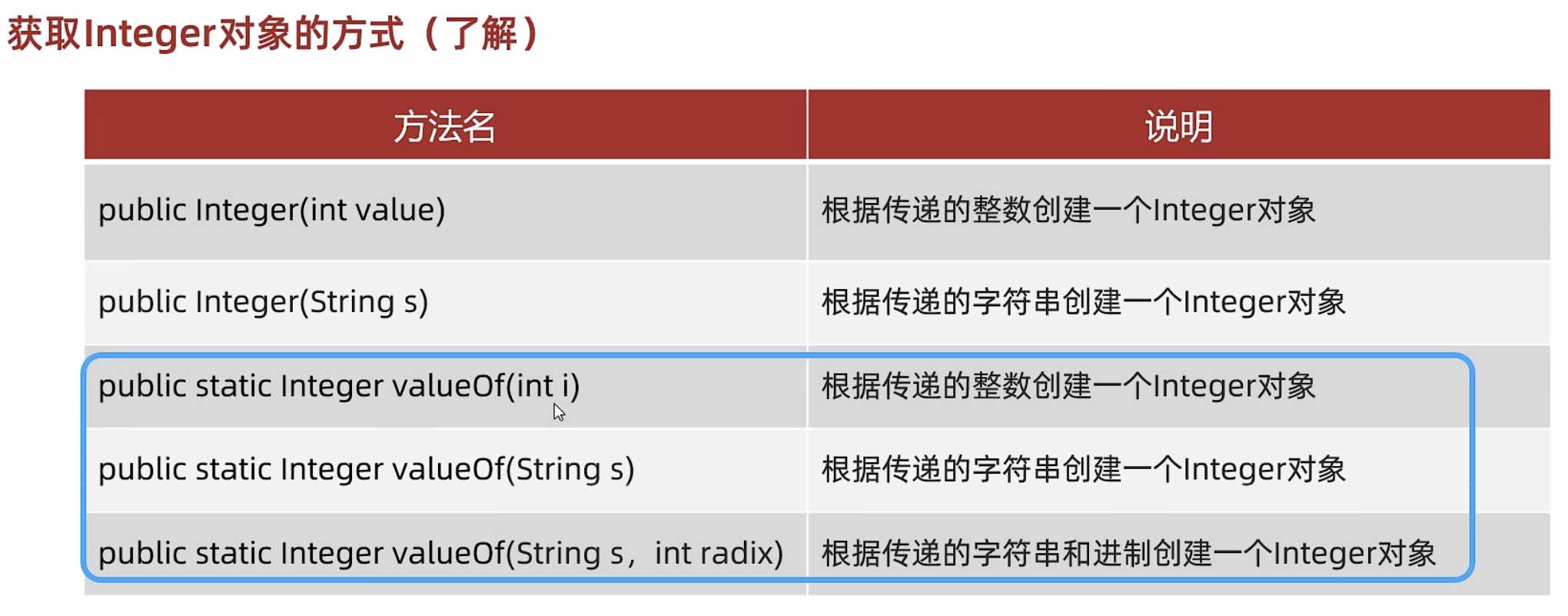
获取Integer对象的方式
获取integer对象方式
两种方式获取对象的区别:
new关键字每一次new都创建一个新的对象,所以地址值不同。
valueof底层将-128-127创建好数组,127之内的返回已经创建好的数组。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
//以前的包装类如何进行计算
//1.把对象进行拆箱,变成基本数据类型。
//2.计算
int result = i1 . intValue () + i2 . intValue ;
//3.把得到的结果再次进行装箱
Integer i3 = new Integer ( result );
//JDK5提出自动装箱和自动拆箱机制
//自动装箱:把基本数据类型自动变成其对应的包装类
//自动拆箱:把包装类自动变成其对象的基本数据类型
Integer i = 10 ; //在底层,还会调用静态方法valueOf得到一个Inter对象。自动装箱
//自动拆箱
Integer i2 = new Integer ( 10 );
int i = i2 ;
//JDK5之后,int和Integer可以看作同一个东西,因为内部可以自动转化。
Integer成员方法
public static String toBinaryString(int i) 得到二进制 public static String toOctalString(int i) 得到八进制 public static String toHexString(int i 得到十六进制 public static int parselent(String s) 将字符串类型的整数转成int类型的整数 1
2
3
4
5
6
//把整数变成二进制
String str1 = Integer . toBinaryString ( 100 );
//将字符串类型的整数转成int类型的整数
int i = Integer . parseInt ( "123" );
//在类型转换的时候,括号里面只能是数字不能是其他,否则代码会报错。
//8中包装类中,除了Charcter都有对应的parseXXX方法进行类型转换。
查找算法
基本查找
基本查找也叫做顺序查找。
说明:顺序查找适合于存储结构为数组或者链表。
基本思想:顺序查找也称为线形查找,属于无序查找算法。从数据结构线的一端开始,顺序扫描,依次将遍历到的结点与要查找的值相比较,若相等则表示查找成功;若遍历结束仍没有找到相同的,表示查找失败。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
public class A01_BasicSearchDemo1 {
public static void main ( String [] args ) {
//基本查找/顺序查找
//核心:
//从0索引开始挨个往后查找
//需求:定义一个方法利用基本查找,查询某个元素是否存在
//数据如下:{131, 127, 147, 81, 103, 23, 7, 79}
int [] arr = { 131 , 127 , 147 , 81 , 103 , 23 , 7 , 79 };
int number = 82 ;
System . out . println ( basicSearch ( arr , number ));
}
//参数:
//一:数组
//二:要查找的元素
//返回值:
//元素是否存在
public static boolean basicSearch ( int [] arr , int number ){
//利用基本查找来查找number在数组中是否存在
for ( int i = 0 ; i < arr . length ; i ++ ) {
if ( arr [ i ] == number ){
return true ;
}
}
return false ;
}
}
二分查找
二分查找也叫做折半查找。
说明:元素必须是有序的,从小到大,或者从大到小都是可以的。
如果是无序的,也可以先进行排序。但是排序之后,会改变原有数据的顺序,查找出来元素位置跟原来的元素可能是不一样的,所以排序之后再查找只能判断当前数据是否在容器当中,返回的索引无实际的意义。
基本思想:也称为是折半查找,属于有序查找算法。用给定值先与中间结点比较。比较完之后有三种情况:
相等说明找到了。 要查找的数据比中间节点小,说明要查找的数字在中间节点左边。 要查找的数据比中间节点大,说明要查找的数字在中间节点右边。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
package com.itheima.search ;
public class A02_BinarySearchDemo1 {
public static void main ( String [] args ) {
//二分查找/折半查找
//核心:
//每次排除一半的查找范围
//需求:定义一个方法利用二分查找,查询某个元素在数组中的索引
//数据如下:{7, 23, 79, 81, 103, 127, 131, 147}
int [] arr = { 7 , 23 , 79 , 81 , 103 , 127 , 131 , 147 };
System . out . println ( binarySearch ( arr , 150 ));
}
public static int binarySearch ( int [] arr , int number ){
//1.定义两个变量记录要查找的范围
int min = 0 ;
int max = arr . length - 1 ;
//2.利用循环不断的去找要查找的数据
while ( true ){
if ( min > max ){
return - 1 ;
}
//3.找到min和max的中间位置
int mid = ( min + max ) / 2 ;
//4.拿着mid指向的元素跟要查找的元素进行比较
if ( arr [ mid ] > number ){
//4.1 number在mid的左边
//min不变,max = mid - 1;
max = mid - 1 ;
} else if ( arr [ mid ] < number ){
//4.2 number在mid的右边
//max不变,min = mid + 1;
min = mid + 1 ;
} else {
//4.3 number跟mid指向的元素一样
//找到了
return mid ;
}
}
}
}
插值查找
二分查找中查找点计算如下:
mid=(low+high)/2, 即mid=low+1/2*(high-low);
我们可以将查找的点改进为如下:
mid=low+(key-a[low])/(a[high]-a[low])*(high-low),
这样,让mid值的变化更靠近关键字key,这样也就间接地减少了比较次数。
基本思想:基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。当然,差值查找也属于有序查找。
细节:对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好的多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
代码跟二分查找类似,只要修改一下mid的计算方式即可。
斐波那契查找
基本思想:也是二分查找的一种提升算法,通过运用黄金比例的概念在数列中选择查找点进行查找,提高查找效率。同样地,斐波那契查找也属于一种有序查找算法。
斐波那契查找也是在二分查找的基础上进行了优化,优化中间点mid的计算方式即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
public class FeiBoSearchDemo {
public static int maxSize = 20 ;
public static void main ( String [] args ) {
int [] arr = { 1 , 8 , 10 , 89 , 1000 , 1234 };
System . out . println ( search ( arr , 1234 ));
}
public static int [] getFeiBo () {
int [] arr = new int [ maxSize ] ;
arr [ 0 ] = 1 ;
arr [ 1 ] = 1 ;
for ( int i = 2 ; i < maxSize ; i ++ ) {
arr [ i ] = arr [ i - 1 ] + arr [ i - 2 ] ;
}
return arr ;
}
public static int search ( int [] arr , int key ) {
int low = 0 ;
int high = arr . length - 1 ;
//表示斐波那契数分割数的下标值
int index = 0 ;
int mid = 0 ;
//调用斐波那契数列
int [] f = getFeiBo ();
//获取斐波那契分割数值的下标
while ( high > ( f [ index ] - 1 )) {
index ++ ;
}
//因为f[k]值可能大于a的长度,因此需要使用Arrays工具类,构造一个新法数组,并指向temp[],不足的部分会使用0补齐
int [] temp = Arrays . copyOf ( arr , f [ index ] );
//实际需要使用arr数组的最后一个数来填充不足的部分
for ( int i = high + 1 ; i < temp . length ; i ++ ) {
temp [ i ] = arr [ high ] ;
}
//使用while循环处理,找到key值
while ( low <= high ) {
mid = low + f [ index - 1 ] - 1 ;
if ( key < temp [ mid ] ) { //向数组的前面部分进行查找
high = mid - 1 ;
/*
对k--进行理解
1.全部元素=前面的元素+后面的元素
2.f[k]=k[k-1]+f[k-2]
因为前面有k-1个元素没所以可以继续分为f[k-1]=f[k-2]+f[k-3]
即在f[k-1]的前面继续查找k--
即下次循环,mid=f[k-1-1]-1
*/
index -- ;
} else if ( key > temp [ mid ] ) { //向数组的后面的部分进行查找
low = mid + 1 ;
index -= 2 ;
} else { //找到了
//需要确定返回的是哪个下标
if ( mid <= high ) {
return mid ;
} else {
return high ;
}
}
}
return - 1 ;
}
}
分块查找
当数据表中的数据元素很多时,可以采用分块查找。
汲取了顺序查找和折半查找各自的优点,既有动态结构,又适于快速查找。
分块查找适用于数据较多,但是数据不会发生变化的情况,如果需要一边添加一边查找,建议使用哈希查找。
分块查找的过程:
需要把数据分成N多小块,块与块之间不能有数据重复的交集。 给每一块创建对象单独存储到数组当中 查找数据的时候,先在数组查,当前数据属于哪一块 再到这一块中顺序查找 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
package com.itheima.search ;
public class A03_BlockSearchDemo {
public static void main ( String [] args ) {
/*
分块查找
核心思想:
块内无序,块间有序
实现步骤:
1.创建数组blockArr存放每一个块对象的信息
2.先查找blockArr确定要查找的数据属于哪一块
3.再单独遍历这一块数据即可
*/
int [] arr = { 16 , 5 , 9 , 12 , 21 , 18 ,
32 , 23 , 37 , 26 , 45 , 34 ,
50 , 48 , 61 , 52 , 73 , 66 };
//创建三个块的对象
Block b1 = new Block ( 21 , 0 , 5 );
Block b2 = new Block ( 45 , 6 , 11 );
Block b3 = new Block ( 73 , 12 , 17 );
//定义数组用来管理三个块的对象(索引表)
Block [] blockArr = { b1 , b2 , b3 };
//定义一个变量用来记录要查找的元素
int number = 37 ;
//调用方法,传递索引表,数组,要查找的元素
int index = getIndex ( blockArr , arr , number );
//打印一下
System . out . println ( index );
}
//利用分块查找的原理,查询number的索引
private static int getIndex ( Block [] blockArr , int [] arr , int number ) {
//1.确定number是在那一块当中
int indexBlock = findIndexBlock ( blockArr , number );
if ( indexBlock == - 1 ){
//表示number不在数组当中
return - 1 ;
}
//2.获取这一块的起始索引和结束索引 --- 30
// Block b1 = new Block(21,0,5); ---- 0
// Block b2 = new Block(45,6,11); ---- 1
// Block b3 = new Block(73,12,17); ---- 2
int startIndex = blockArr [ indexBlock ] . getStartIndex ();
int endIndex = blockArr [ indexBlock ] . getEndIndex ();
//3.遍历
for ( int i = startIndex ; i <= endIndex ; i ++ ) {
if ( arr [ i ] == number ){
return i ;
}
}
return - 1 ;
}
//定义一个方法,用来确定number在哪一块当中
public static int findIndexBlock ( Block [] blockArr , int number ){ //100
//从0索引开始遍历blockArr,如果number小于max,那么就表示number是在这一块当中的
for ( int i = 0 ; i < blockArr . length ; i ++ ) {
if ( number <= blockArr [ i ] . getMax ()){
return i ;
}
}
return - 1 ;
}
}
class Block {
private int max ; //最大值
private int startIndex ; //起始索引
private int endIndex ; //结束索引
public Block () {
}
public Block ( int max , int startIndex , int endIndex ) {
this . max = max ;
this . startIndex = startIndex ;
this . endIndex = endIndex ;
}
/**
* 获取
* @return max
*/
public int getMax () {
return max ;
}
/**
* 设置
* @param max
*/
public void setMax ( int max ) {
this . max = max ;
}
/**
* 获取
* @return startIndex
*/
public int getStartIndex () {
return startIndex ;
}
/**
* 设置
* @param startIndex
*/
public void setStartIndex ( int startIndex ) {
this . startIndex = startIndex ;
}
/**
* 获取
* @return endIndex
*/
public int getEndIndex () {
return endIndex ;
}
/**
* 设置
* @param endIndex
*/
public void setEndIndex ( int endIndex ) {
this . endIndex = endIndex ;
}
public String toString () {
return "Block{max = " + max + ", startIndex = " + startIndex + ", endIndex = " + endIndex + "}" ;
}
}
排序算法
冒泡排序
冒泡排序(Bubble Sort)也是一种简单直观的排序算法。
它重复的遍历过要排序的数列,一次比较相邻的两个元素,如果他们的顺序错误就把他们交换过来。
这个算法的名字由来是因为越大的元素会经由交换慢慢"浮"到最后面。
算法步骤
1
2
3
4
5
6
7
8
9
10
11
12
public static void bubbleSort ( int [] arr ) {
int n = arr . length ;
for ( int i = 0 ; i < n - 1 ; i ++ ) {
for ( int j = 0 ; j < n - i - 1 ; j ++ ) {
if ( arr [ j ] > arr [ j + 1 ] ) {
int temp = arr [ j ] ;
arr [ j ] = arr [ j + 1 ] ;
arr [ j + 1 ] = temp ;
}
}
}
}
选择排序
算法步骤
从0索引开始,跟后面的元素一一比较
小的放前面,大的放后面
第一次循环结束后,最小的数据已经确定
第二次循环从1索引开始以此类推
第三轮循环从2索引开始以此类推
第四轮循环从3索引开始以此类推。
插入排序
插入排序的代码实现虽然没有冒泡排序和选择排序那么简单粗暴,但它的原理应该是最容易理解的了,因为只要打过扑克牌的人都应该能够秒懂。插入排序是一种最简单直观的排序算法,它的工作原理是通过创建有序序列和无序序列,然后再遍历无序序列得到里面每一个数字,把每一个数字插入到有序序列中正确的位置。
插入排序在插入的时候,有优化算法,在遍历有序序列找正确位置时,可以采取二分查找。
插入排序步骤
将0索引的元素到N索引的元素看做是有序的,把N+1索引的元素到最后一个当成是无序的。
遍历无序的数据,将遍历到的元素插入有序序列中适当的位置,如遇到相同数据,插在后面。
N的范围:0~最大索引
1
2
3
4
5
6
7
8
9
10
11
12
public static void insertionSort ( int [] arr ) {
int n = arr . length ;
for ( int i = 1 ; i < n ; i ++ ) {
int key = arr [ i ] ;
int j = i - 1 ;
while ( j >= 0 && arr [ j ] > key ) {
arr [ j + 1 ] = arr [ j ] ;
j -- ;
}
arr [ j + 1 ] = key ;
}
}
快速排序
快速排序是由东尼·霍尔所发展的一种排序算法。
快速排序又是一种分而治之思想在排序算法上的典型应用。
快速排序的名字起的是简单粗暴,因为一听到这个名字你就知道它存在的意义,就是快,而且效率高!
它是处理大数据最快的排序算法之一了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
private static void sort ( int [] arr , int low , int high ) {
// 枢轴的索引
int pivotIndex ;
if ( low < high ) {
// 将数组一分为二,并返回枢轴的索引
pivotIndex = partition ( arr , low , high );
// 对低子表递归排序
sort ( arr , low , pivotIndex - 1 );
// 对高子表递归排序
sort ( arr , pivotIndex + 1 , high );
}
}
private static int partition ( int [] arr , int low , int high ) {
int pivot = arr [ low ] ;
while ( low < high ) {
while ( low < high && arr [ high ] >= pivot ) high -- ; //找到右边比基准小的
arr [ low ] = a [ high ] ;
while ( low < high && arr [ low ] <= pivot ) low ++ ; //找到左边比基准大的
arr [ high ] = arr [ low ] ;
}
arr [ low ] = pivot ;
return low ;
}
算法步骤
从数列中挑出一个元素,一般都是左边第一个数字,称为 “基准数”;
创建两个指针,一个从前往后走,一个从后往前走。
先执行后面的指针,找出第一个比基准数小的数字
再执行前面的指针,找出第一个比基准数大的数字
交换两个指针指向的数字
直到两个指针相遇
将基准数跟指针指向位置的数字交换位置,称之为:基准数归位。
第一轮结束之后,基准数左边的数字都是比基准数小的,基准数右边的数字都是比基准数大的。
把基准数左边看做一个序列,把基准数右边看做一个序列,按照刚刚的规则递归排序
Arrays介绍
Arrays是操作数组的工具类。
Arrays常用方法
public static String toString(数组) 把数组拼接成一个字符串 public static int binarySearch(数组,查找的元素) 二分法查找数组 public static int[] copyOf(原数组,新数组长度) public static int[] copyOfRange(原数组,起始索引,结束索引) public static void fill(数组,元素) 填充数组 public static void sort(数组) 按照默认方式进行数组排序 public static void sort(数组,排序规则) 按照指定规则排序 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public class SortDemo {
public static void main ( String [] args ) {
Integer [] arr = { 2 , 3 , 1 , 5 , 7 , 8 , 4 , 9 };
//底层原理:利用插入排序+二分查找的方式进行排序。
//默认把0索引的数据当作是有序的序列,1索引到最后是无序的序列。
//遍历无序的序列得到每一个元素。假设当前遍历得到的元素是A元素
//把A往有序序列进行插入,在插入的时候,是利用二分查找确定A元素的插入点。
//拿着A元素跟插入点进行比较,比较规则就是compare方法的方法体
//如果返回方法的返回值是负数,拿着A继续跟前面的元素进行比较
//如果返回方法的返回值是正数,拿着A继续跟后面的元素进行比较
//如果返回方法的返回值是0,拿着A继续跟后面的元素进行比较
//知道能确定A的最终位置
//compare方法的形参:
//参数一 o1:表示无序序列中得到的每一个元素
//参数二 o2:有序序列中的元素
//返回值
//负数:表示当前要插入的元素是小的,放在前面。
//正数:表示当前要插入的元素是大的,放在后面。
//0:表示当前要插入的元素和现在的元素一样,放在后面。
//简单理解:o1 - o2 升序 o2 - o1 降序
Arrays . sort ( arr , new Comparator < Integer > () {
@Override
public int compare ( Integer o1 , Integer o2 ) {
return o1 - o2 ;
}
});
System . out . println ( Arrays . toString ( arr ));
}
}
Lambda表达式
1
2
3
4
5
6
7
8
9
10
11
Arrays . sort ( arr , new Comparator < Integer > () {
@Override
public int compare ( Integer o1 , Integer o2 ) {
return o1 - o2 ;
}
});
//lambda表达式
Arrays . sort ( arr , ( Integer o1 , Integer o2 ) -> {
return o1 - o2 ;
}
);
函数式编程
函数式编程(Functional programming)是一种思想特点。这种思想忽略面向对象复杂的语法,强调做什么,而不是谁去做。
面向对象:先找对象,让对象做事情。
Lambda表达式是JDK8开始后的一种新语法形式。
()对应方法的形参 ->固定格式 {} 对应方法的方法体 注意事项
Lambda表达式可以用来简化匿名内部类的书写。 Lambda表达式只能简化==函数式接口==的匿名内部类的写法。有且仅有一个抽象方法的接口叫做函数式接口,接口上方可以加@FuncitonalInterface注解 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public static void main (){
method ( new Swim (){
@Override
public void swimming () {
System . out . println ( "正在游泳" )
}
});
//利用lambda改写
method (() -> {
System . out . println ( "正在游泳" )
});
}
public static void method ( Swim s ) {
s . swimming ();
}
interface Swim {
public abstract void swimming ();
}
Lambda表达式的省略写法
省略核心:可推导,可省略。
省略规则:
参数类型可以省略不写。 如果只有一个参数,参数类型可以省略不写,同时()也可以省略。 如果Lambda表达式的方法体只有一行,大括号,分号return可以省略不写,需要同时省略。 1
2
3
4
5
6
7
8
9
10
11
12
13
Arrays . sort ( arr , new Comparator < Integer > () {
@Override
public int compare ( Integer o1 , Integer o2 ) {
return o1 - o2 ;
}
});
//lambda表达式完整格式
Arrays . sort ( arr , ( Integer o1 , Integer o2 ) -> {
return o1 - o2 ;
}
);
//lambda表达式省略写法
Arrays . sort ( arr , ( o1 , o2 ) -> o1 - o2 );
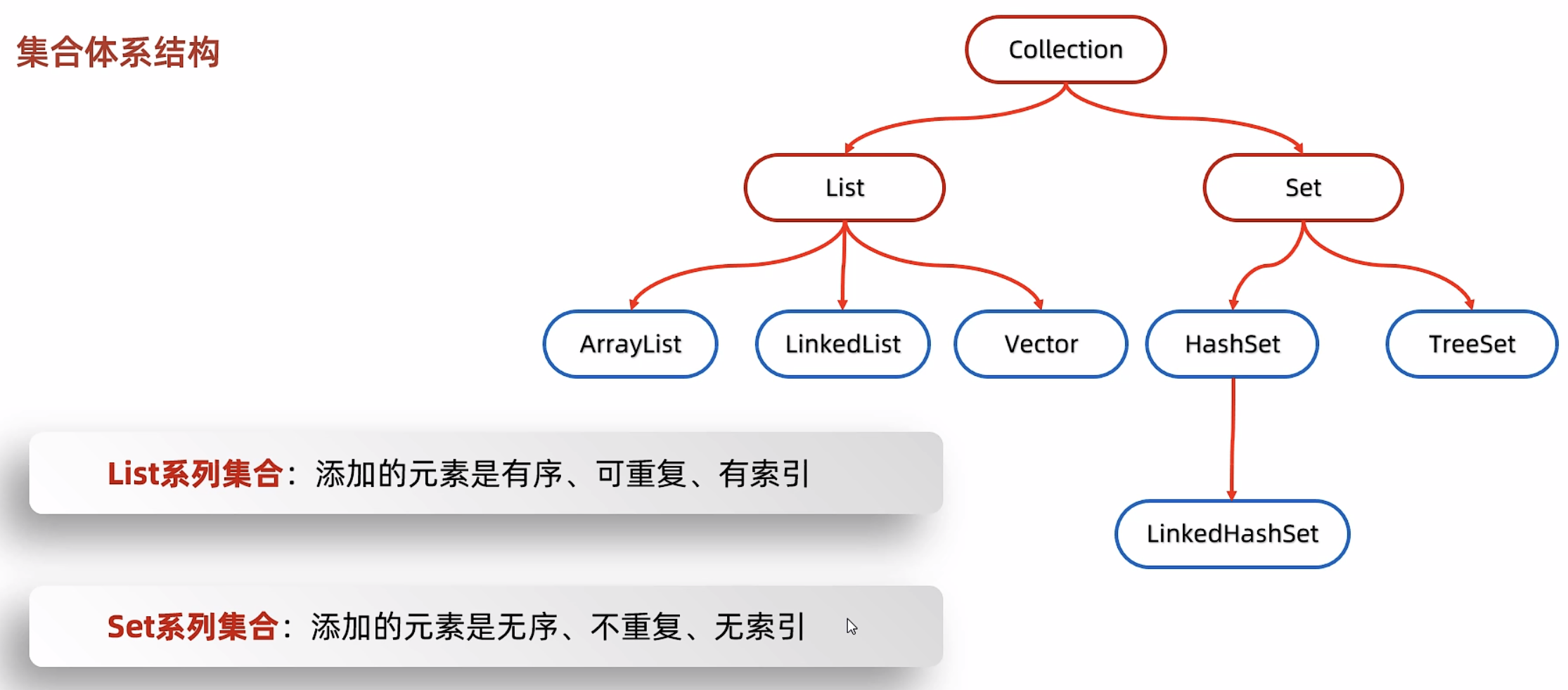
集合整体上可以分为两类:单列集合Collection和双列集合Map。
单列体系结构
双列体系结构
图中,红色表示接口,蓝色表示实现类。
Collection介绍
Collection是单列集合的祖宗接口,他的功能是全部单列集合都可以继承使用的。
Collection常用方法
方法名称 说明 pulic boolean add(E e) 把给定的对象添加到当前集合中 public void clear() 清空集合中所有的元素 public boolean remove(E e) 把给定的对象在集合中删除 public boolean contains(Object obj) 判断当前集合中是否包含给定的对象 public boolean isEmpty() 判断当前集合是否为空 public int size() 返回集合中欧给元素的个数/集合的长度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//Collection是一个接口,不能直接创建他的对象。所有学习方法只能创建他的实现类的对象。本例中采用ArrayList
Collection < String > coll = new ArrayList <> (); //利用多态的方式创建对象
//1.添加元素
//如果往List系列集合中添加数据,那么方法永远返回true。因为List系列允许元素重复。
//如果往set系列集合中添加数据,如果添加元素不存在则返回true,否则返回false。
coll . add ( "aa" );
//2.清空元素
coll , clear ();
//3.删除
//因为Collection里面定义的是共性的方法,所以不能通过索引进行删除。只能通过元素的对象进行删除。
//删除失败返回false,如果删除的元素不存在,那么就会删除失败。
coll . remove ( "aa" );
//4.判断元素是否包含
//底层实现依赖equals方法,如果存储的是自定义对象,在JavaBean类中,一定要重写equals方法。
//如果没有重写,则依赖Object类中的equals方法进行判断,即依赖地址值进行判断。
bool contains = coll . contains ( "aa" );
//5.判断集合是否为空
//底层实现为判断size
bool isEmpty = coll . isEmpty ();
//6.获取集合的长度
int size = coll . size ();
collection的遍历方式
迭代器遍历
迭代器在java中的类是Iterator,迭代器是集合专用的遍历方式。迭代器不依赖索引。
Collection集合获取迭代器与常用方法
方法名称 方法说明 Iterator< E > iterator() 返回迭代器对象,默认指向当前集合的0索引 boolean hashNext() 判断当前位置是否有元素,有元素返回true,没有元素返回false E next() 获取当前位置的元素,并将迭代器对象移向下一个位置
1
2
3
4
5
6
7
8
//1.创建指针
Iterator < String > it = list . iterator ();
//2.判断是否有元素
while ( it . hasNext ()) {
//3。获取元素同时移动指针
String str = it . next ();
System . out . println ( str );
}
迭代器细节注意点
报错NoSuchElementException 迭代器遍历完毕,指针不会复位 循环中只能用一次next方法 迭代器遍历时,不能用集合的方法进行增加或者删除 增强for遍历
增强for的底层就是迭代器,为了简化迭代器的代码书写。 JDK5之后出现,其内部原理就是一个Iterator迭代器。 所有的单列集合和数组才能用增强for进行遍历。 增强for格式
1
2
3
4
5
6
7
8
9
for ( 元素的数据类型 变量名 : 数组或者集合 ) {
}
//具体案例
//s其实就是一个第三方变量,在循环的过程中依次表示集合的每一个数据
//Idea快捷键 List.for
for ( String s : List ) {
System . out . println ( s );
}
增强for的细节
修改增强for中的变量,不会改变集合中原本的数据。
Lambda表达式遍历
得益于JDK 8开始的新技术Lambda表达式,提供了一种更简单、更直接的遍历集合的方式。
方法名称 说明 default void forEach(Consumer<? super T> action): 集合Lambda遍历集合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
//1.创建集合并添加元素
Collection < String > coll = new ArrayList <> ();
coll . add ( "1" );
coll . add ( "2" );
coll . add ( "3" );
//2.利用匿名内部类形式
//底层原理:方法遍历集合得到每一个元素,把得到的每一个元素传递给accpet方法
coll . forEach ( new Consumer < String > (){
@Override
//s依次表示集合中的每一个数据
public void accept ( String s ) {
System . out , println ( s );
}
});
//3.Lambda表达式
coll . forEach ( s -> System . out , println ( s ) );
List集合特点
有序:存和取的顺序一致 有索引:可以通过索引操作元素 可重复:存储的元素可以重复 List集合的特有方法
Collection的方法List都继承了 List集合因为有索引,所以多了很多索引操作的方法 方法名称 说明 void add(int index, E element) 在集合中的指定位置插入指定的元素 E remove(int Index) 删除指定索引处的元素,返回被删除的元素 E set(int Index, E element) 修改指定索引处的元素,返回被删除的元素 E get(int Index) 返回指定索引处的元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//1.创建一个集合
List < String > list = new ArrayList <> ();
//2.添加元素
list . add ( "aaa" );
list . add ( "bbb" );
list . add ( "ccc" );
//指定位置添加元素
list . add ( 1 , "ttt" ); //[aaa,ttt,bbb,ccc]
//删除指定索引
String s = list . remove ( 0 );
//修改指定索引
String s1 = list . set ( 0 , "qqq" );
//返回指定索引的元素
String s2 = list . get ( 0 );
List集合的遍历方式
迭代器遍历 遍历过程需要删除元素使用迭代器 列表迭代器遍历 遍历过程中需要添加元素使用列表迭代器 增强for遍历 Lambda表达式遍历 普通for遍历(List存在索引) 遍历时想要操作索引,使用普通for 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
//创建元素并添加元素
List < String > list = new ArrayList <> ();
list . add ( "AAA" );
list . add ( "BBB" );
list . add ( "CCC" );
//1.迭代器
Iterator < String > it = list . iterator ();
while ( list . hasNext ()) {
String str = it . next ();
System . out . println ( str );
}
//2.增强for
for ( String s : list ) {
System . out . println ( s );
}
//3.Lambda表达式
coll . forEach ( s -> System . out , println ( s ));
//4.普通for循环
for ( int i = 0 ; i < list . size (); i ++ ) {
String str = list . get ( i );
System . out . println ( s );
}
//5.列表迭代器
//与迭代器相比添加了一个方法:在遍历的过程中可以添加元素
ListIterator < String > it = list . listIterator ();
while ( it . hasNext ()) {
String str = it . next ();
if ( str . equals ( "BBB" )) {
it . add ( "qqq" )
}
System . out . println ( str );
}
ArrayList集合底层原理
利用空参构造的集合,在底层创建一个默认长度为0的数组。 添加第一个元素时,底层会创建一个新的长度为10的数组。 存满时,会扩容1.5倍。 如果一次添加多个元素,1.5倍放不下,则新创建的数组的长度以实际为准。 LinkedList集合
底层数据结构是双链表,查询慢,增删块,操作首尾元素速度块。 LinkedList方法
特有方法 说明 public void addFirst(E e) 在该列表开头插入指定的元素 public void addLast(E e) 将指定的元素追加到此列表的末尾 public E getFirst() 返回列表的第一个元素 public E getLast() 返回列表的最后一个元素 public E removeFirst() 从此列表中删除并放回第一个元素 public E removeLast() 从此列表中删除并放回最后一个元素
泛型
泛型是JDK5引入的特性,可以在编译阶段约束操作的数据类型,并进行检查。
泛型的格式:<数据类型>
注意:==泛型只支持引用数据类型。==
如果没有给集合指定类型,默认认为所有的数据类型都是Object类型,此时可以往集合添加任意的数据类型。此时的坏处时,获取数据的时候,无法使用特有行为。此时推出泛型,在添加数据的时候就把类型进行统一,而且在获取数据的时候不需要额外强转。
泛型的好处
统一数据类型。 把运行期间的问题提到了编译期间,避免强制类型转换可能出现的异常,因为在编译阶段类型就能确定下来。 拓展:java中的泛型是伪泛型。
泛型的细节
泛型中不能写基本数据类型。 指定泛型的具体类型后,传递数据时,可以传入该类类型或者其子类型。 如果不写泛型,类型默认是Object。 泛型可以在很多地方定义
类后面 泛型类 方法上面 泛型方法 接口后面 泛型接口 泛型类
使用场景:当一个类中,某个变量的数据类型不确定时,就可以定义带有泛型的类。
1
2
3
4
5
6
7
8
9
//格式
修饰符 class 类名 < 类型 > {
}
//举例
public class ArrayList < E > { //创建类对象时,E就确定类型。
}
//此处E可以理解为变量,但是不是用来接收数据的,而是记录数据的类型,可以写成:T(Type)、E(Element)、K(Key)、V(Variable)等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
//自己编写一个带有泛型的ArrayList
/*
* 当编写一个类时,如果不确定类型,那么这个类可以定义为泛型类。
**/
public class MyArrayList < E > {
Object [] obj = new Object [ 10 ] ;
int size ;
/*
E:表示不确定的类型。该类型在类的后面已经定义过了。
e:形参的名字,变量名。
**/
public boolean add ( E e ) {
obj [ size ] = e ;
size ++ ;
return true ;
}
public E get ( int index ) {
return ( E ) obj [ index ] ;
}
public String toString () {
return Arrays . toString ( obj );
}
}
泛型方法
方法中形参类型不确定时,可以使用类名后面定义的泛型< E >。如果类中只有一个方法的形参不确定,此时没有必要把泛型定义在后面,此时可以把泛型定义在方法上。
当方法中参数类型不确定时
使用类名后面定义的泛型,类中的所有方法都能用。 在方法申明上定义自己的泛型,只有本方法能用。 1
2
3
4
5
6
7
8
9
//格式
修饰符 < 类型 > 返回值类型 方法名 ( 类型 变量名 ) {
}
//举例
public < T > void show ( T t ) {
}
//此处T可以理解为变量,但是不是用来接收数据的,而是记录数据的类型,可以写成:T(Type)、E(Element)、K(Key)、V(Variable)等
1
2
3
4
5
6
7
8
9
10
11
12
13
//定义一个工具类ListUtil 类中定义静态方法addAll,用来添加多个集合元素
public class ListUtil {
private ListUtil (){};
/*
*参数一:集合
*参数二到最后:要添加的元素
**/
public static < E > void addAll ( ArrayList < E > list , E e1 , E e2 , E e3 ) {
list . add ( e1 );
list . add ( e2 );
list . add ( e3 );
}
}
泛型接口
1
2
3
4
5
6
7
8
//格式
修饰符 interface 接口名 < 类型 > {
}
//举例
public interface List < E > {
}
如何使用一个带泛型的接口
实现类给出具体类型 实现类延续泛型,创建对象时再确定 1
2
3
4
5
6
7
8
//1.实现类给出具体的类型
public class MyArrayList implments List < String > {
}
//2.实现类延续泛型,创建实现类对象时再确定类型
public class MyArrayList < E > implments List < E > {
}
泛型的继承和通配符
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
//ye fu zi三个类存在继承关系
ArrayList < Ye > list1 = new arrayList <> ();
ArrayList < Fu > list1 = new arrayList <> ();
ArrayList < Zi > list1 = new arrayList <> ();
method ( list1 ); //正常
//报错,泛型不具备继承性
method ( list2 );
method ( list3 );
//正确运行,数据具备继承性
list1 . add ( new Ye ());
list1 . add ( new Fu ());
list1 . add ( new Zi ());
public static < Ye > void method ( ArrayList < Ye > list ) {
}
//泛型的通配符
//?super E:传递E或E的父类
//?extends E:传递E或E的子类
public static void method ( ArrayList <? super ye > list ) {
}
public static void method ( ArrayList <? extends ye > list ) {
}
使用场景
如果再定义类、方法、接口时类型不确定,就可以定义泛型类、泛型方法、泛型接口。 如果类型不确定,但是能知道以后只能传递某个继承体系中的,就可以使用泛型通配符。 Set系列集合特点
无序:存取顺序不一致 不重复:可以去除重复 无索引:没有带索引的方法,所以不能用普通for循环遍历,也不能通过索引来获取元素。 Set集合的实现类
HashSet:无序、不重复、无索引 LinkedHashSet:有序、不重复、无索引 TreeSet:可排序、无索引、不重复 set接口中的方法基本上与Collection的API一致。
HashSet底层原理
HashSet集合底层采取哈希表存储数据 哈希表是一种对于增删改查数据性能都较好的结构 哈希表组成
JDK8之前:数组+链表 JDK8开始:数组+链表+红黑树 哈希值
根据hashCode方法计算出来的int类型的整数 该方法定义在object类中,所有的对象都可以调用,默认使用地址值进行计算 一般情况下,会重写hashcode方法,利用对象内部的属性值计算哈希值 对象的哈希值特点
如果没有重写hashCode方法,不同对象计算出的哈希值是不同的 如果已经重写hashCode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的 在小部分情况下,不同属性值或者不同地址值计算出来的哈希值也有可能是一样的(哈希碰撞) HashSet JDK8以前的底层原理
1
2
3
4
5
6
7
8
9
//1.创建一个默认长度16,默认加载因子为0.75的数组,数组名table
HashSet < String > hm = new HashSet <> ();
//2.根据元素的哈希值跟数组的长度计算出应存入的位置。
int index = ( 数组长度 - 1 ) & 哈希值 ;
//3.判断当前位置是否为null,如果是null直接存入
//4.如果位置不为null,表示有元素,则调用equals方法比较属性值
//5.如果equals比较结果为true,不存入,如果是false,则存入数组,形成链表
//不同点:JDK8之前,新元素入数组,老元素挂在下面 JDK8之后,新元素直接挂在老元素下面
//扩容时期:当数组存的元素>16 * 0.75 数组就会扩容成原先的两倍。 链表的长度大于8而且数组的长度大于等于64链表就会变成红黑树。
LinkedHashSet底层原理
有序、不重复、无索引 这里的有序指的是保证存储和取出的元素顺序一致 原理:底层数据结构依然是哈希表,只是每个元素又额外的多了一个双链表的机制记录存储的顺序 TreeSet特点
不重复、无索引、可排序 可排序:按照元素的默认规则(从小到大)排序 TreeSet集合底层是基于红黑树数据结构实现排序的、增删改查性能都较好 1
2
3
4
5
6
7
8
9
10
//1.创建TreeSet对象
TreeSet < Integer > ts = new TreeSet <> ();
//2.添加元素
ts . add ( 5 );
ts . add ( 2 );
ts . add ( 4 );
ts . add ( 3 );
ts . add ( 1 );
//3.打印集合
System . out . println ( ts ) //[1,2,3,4,5]
TreeSet的两种比较方式
方式1:默认排序/自然排序”Javabean类实现Comparable接口指定比较规则 方式2:创建TreeSet对象时候,传递比较器Comparator指定规则 使用原则:默认使用第一种,如果第一种不能满足需求,就使用第二种。
双列集合的特点
双列集合一次需要存一对数据,分别为键和值 键不能重复,值可以重复 键和值是一一对应的关系,每一个键只能找到自己对应的值 键+值这个整体称之为键值对或者键值对对象,在Java中叫做Entry对象。 Map集合的常见API
Map是双列集合的顶层接口,他的功能是全部双列集合都可以继承使用的。
方法名称 说明 V put(K key, V value) 添加元素 V remove(Object key) 根据键删除键值对元素 void clear() 移除所有的键值对元素 boolean containsKey(Object key) 判断集合是否包含指定的键 boolean containsValue(Object value) 判断集合是否包含指定的值 boolean isEmpty() 判断集合是否为空 int size() 集合的长度,也就是集合中键值对的个数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
//1.创建Map集合的对象
Map < String , String > m = new HashMap <> ();
//2.添加元素
//put方法的细节:添加/覆盖
//在添加数据的时候,如果键不存在,直接把键值对对象添加到map当中,方法返回null
//如果键是存在的,那么会把原有的键值对覆盖,会把覆盖的值进行返回
m . put ( "三年二班" , "周杰伦" );
//删除
String v = m . remove ( "三年二班" ); //周杰伦
//情况
m . clear ();
//判断是否包含
boolean keyResult = m . containsKey ( "三年二班" );
boolean valueResult = m . containsValue ( "周杰伦" );
//判断是否为空
boolean result = m . isEmpty ();
//集合的长度
int num = m . size ();
Map的遍历方式
键找值遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//1.创建map的对象
Map < String , String > map = new HashMap <> ();
//2.添加元素
map . put ( "A" , "1" );
map . put ( "B" , "2" );
map . put ( "C" , "3" );
//3.键找值遍历
//3.1获取所有的键到单列结合中
Set < String > keys = map . keySet ();
//3.2遍历单列集合得到每一个键
for ( String key : keys ) {
//3.3利用键获取值
String value = map . get ( key );
}
键值对遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
//1.创建map的对象
Map < String , String > map = new HashMap <> ();
//2.添加元素
map . put ( "A" , "1" );
map . put ( "B" , "2" );
map . put ( "C" , "3" );
//3.键值对遍历
//3.1获取所有的键值对对象,返回一个Set集合
Set < Map . Entry < String , String >> entries = map . entrySet ();
//3.2遍历entries集合得到每一个键值对对象
for ( Map . Entry < String , String > entry : entries ) {
//3.3利用entry调用get方法获取键和值
String key = entry . getKey ();
String value = entry . getValue ();
}
Lambda表达式
方法名称 说明 default void forEach(BiConsumer<? super k, ? super V> action) 结合Lambda遍历Map集合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
//1.创建map的对象
Map < String , String > map = new HashMap <> ();
//2.添加元素
map . put ( "A" , "1" );
map . put ( "B" , "2" );
map . put ( "C" , "3" );
//3.Lambda表达式遍历
map . forEach ( new BiConsumer < String , String > (){
@Override
public void accept ( String key , String value ) {
System . out . println ( key + "=" + value );
}
});
//底层原理:键值对遍历得到每一个键和值,再调用accept方法
map . forEach (( key , value ) -> System . out . println ( key + "=" + value ));
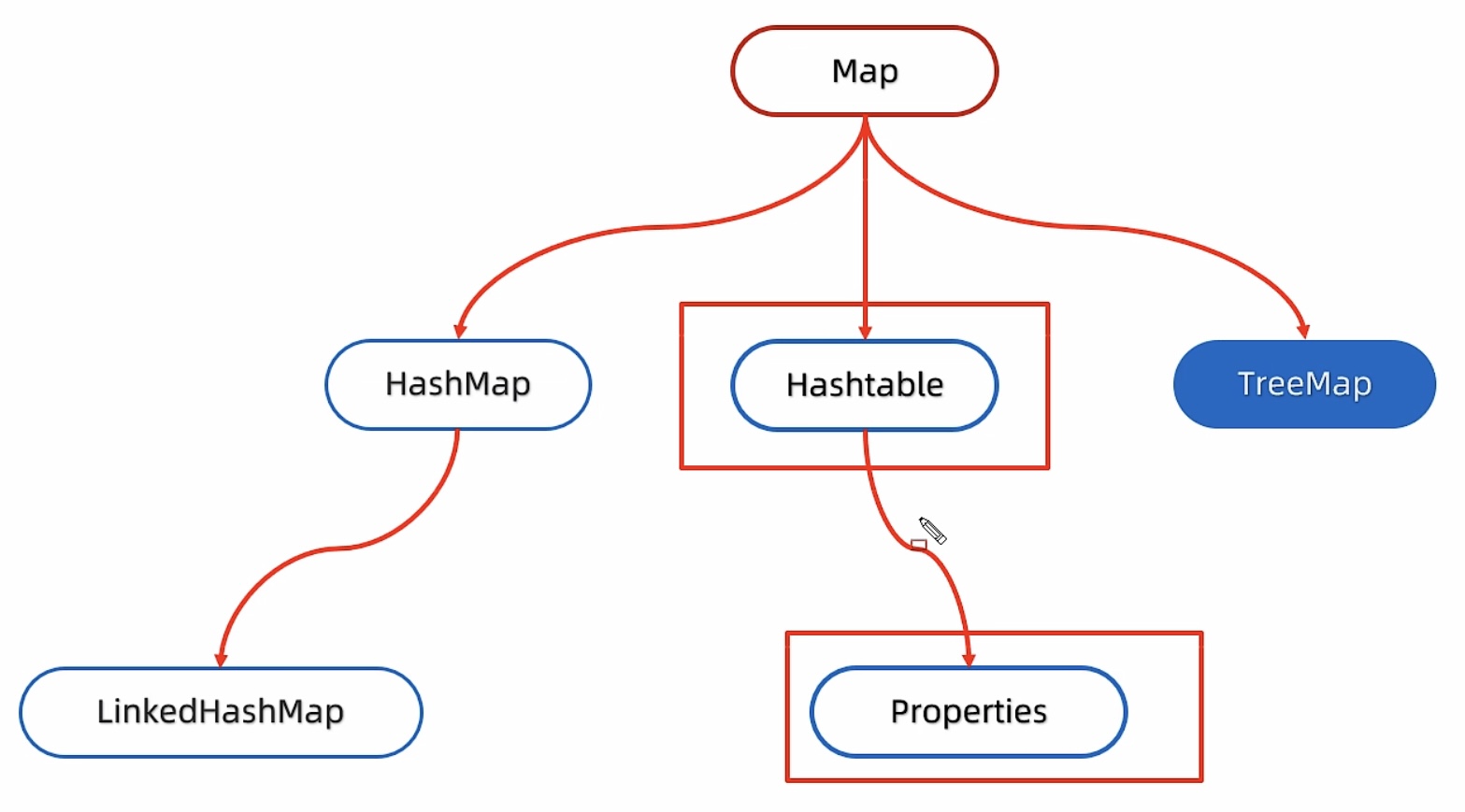
HashMap的特点
HashMap是Map里面的实现类。 没有额外的特有方法,直接使用Map里面的方法就可以。 特点都是由键决定的:无序、不重复、无索引。 HashMap和HashSet的底层原理都是一模一样的,都是哈希表结构。 HashMap的底层原理
大致与HashSet相同,put元素底层会创建Entry对象,根据键的值计算出哈希值。不同之处在于,如果键的属性值相同则覆盖。
HashMap的键位置如果存储的是自定义对象,需要重写HashCode和equals方法。
LinkedHashMap特点
由键决定:有序、不重复、无索引 这里的有序指的是保证存储和取出的顺序一致 原理:底层数据结构依然是哈希表,只是每个键值对元素又额外的多了一个双链表的机制记录存储的顺序。 TreeMap特点
TreeMap和TreeSet底层原理一样,都是红黑树结构的。 由键决定特性:不重复、无索引、可排序 可排序:对键进行排序 注意:默认按照键的从小到大进行排序,也可以自己规定键的排序规则 代码书写规则
实现Comparable接口,指定比较规则 创建集合时传递Comparator对象,指定比较规则 新的统计思想
利用map集合进行统计。如果没有要求对结果排序,默认使用HashMap,如果要求对结果排序则使用TreeMap。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
/*需求:
*字符串"adasdasnfakjsfhjaskfhdajsk"
*统计每个字符出现的次数
*按a(5)b(4)格式输出
*/
//1.定义字符串
String s = "adasdasnfakjsfhjaskfhdajsk" ;
//2.创建集合
TreeMap < Character , Integer > tm = new TreeMap <> ();
//3.遍历字符串得到每一个字符
for ( int i = 0 ; i < s . length (); i ++ ) {
char c = s . charAt ( i );
//拿着C到集合中判断是否存在
if ( tm . containsKey ( c )) {
int count = tm . getValue ( c );
count ++ ;
tm . put ( c , count );
} else {
tm . put ( c , 1 )
}
}
HashMap源码分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
1 . 看源码之前需要了解的一些内容
Node < K , V >[] table 哈希表结构中数组的名字
DEFAULT_INITIAL_CAPACITY : 数组默认长度16
DEFAULT_LOAD_FACTOR : 默认加载因子0 . 75
HashMap里面每一个对象包含以下内容 :
1 . 1 链表中的键值对对象
包含 :
int hash ; //键的哈希值
final K key ; //键
V value ; //值
Node < K , V > next ; //下一个节点的地址值
1 . 2 红黑树中的键值对对象
包含 :
int hash ; //键的哈希值
final K key ; //键
V value ; //值
TreeNode < K , V > parent ; //父节点的地址值
TreeNode < K , V > left ; //左子节点的地址值
TreeNode < K , V > right ; //右子节点的地址值
boolean red ; //节点的颜色
2 . 添加元素
HashMap < String , Integer > hm = new HashMap <> ();
hm . put ( "aaa" , 111 );
hm . put ( "bbb" , 222 );
hm . put ( "ccc" , 333 );
hm . put ( "ddd" , 444 );
hm . put ( "eee" , 555 );
添加元素的时候至少考虑三种情况 :
2 . 1数组位置为null
2 . 2数组位置不为null , 键不重复 , 挂在下面形成链表或者红黑树
2 . 3数组位置不为null , 键重复 , 元素覆盖
//参数一:键
//参数二:值
//返回值:被覆盖元素的值,如果没有覆盖,返回null
public V put ( K key , V value ) {
return putVal ( hash ( key ), key , value , false , true );
}
//利用键计算出对应的哈希值,再把哈希值进行一些额外的处理
//简单理解:返回值就是返回键的哈希值
static final int hash ( Object key ) {
int h ;
return ( key == null ) ? 0 : ( h = key . hashCode ()) ^ ( h >>> 16 );
}
//参数一:键的哈希值
//参数二:键
//参数三:值
//参数四:如果键重复了是否保留
// true,表示老元素的值保留,不会覆盖
// false,表示老元素的值不保留,会进行覆盖
final V putVal ( int hash , K key , V value , boolean onlyIfAbsent , boolean evict ) {
//定义一个局部变量,用来记录哈希表中数组的地址值。
Node < K , V >[] tab ;
//临时的第三方变量,用来记录键值对对象的地址值
Node < K , V > p ;
//表示当前数组的长度
int n ;
//表示索引
int i ;
//把哈希表中数组的地址值,赋值给局部变量tab
tab = table ;
if ( tab == null || ( n = tab . length ) == 0 ){
//1.如果当前是第一次添加数据,底层会创建一个默认长度为16,加载因子为0.75的数组
//2.如果不是第一次添加数据,会看数组中的元素是否达到了扩容的条件
//如果没有达到扩容条件,底层不会做任何操作
//如果达到了扩容条件,底层会把数组扩容为原先的两倍,并把数据全部转移到新的哈希表中
tab = resize ();
//表示把当前数组的长度赋值给n
n = tab . length ;
}
//拿着数组的长度跟键的哈希值进行计算,计算出当前键值对对象,在数组中应存入的位置
i = ( n - 1 ) & hash ; //index
//获取数组中对应元素的数据
p = tab [ i ] ;
if ( p == null ){
//底层会创建一个键值对对象,直接放到数组当中
tab [ i ] = newNode ( hash , key , value , null );
} else {
Node < K , V > e ;
K k ;
//等号的左边:数组中键值对的哈希值
//等号的右边:当前要添加键值对的哈希值
//如果键不一样,此时返回false
//如果键一样,返回true
boolean b1 = p . hash == hash ;
if ( b1 && (( k = p . key ) == key || ( key != null && key . equals ( k )))){
e = p ;
} else if ( p instanceof TreeNode ){
//判断数组中获取出来的键值对是不是红黑树中的节点
//如果是,则调用方法putTreeVal,把当前的节点按照红黑树的规则添加到树当中。
e = (( TreeNode < K , V > ) p ). putTreeVal ( this , tab , hash , key , value );
} else {
//如果从数组中获取出来的键值对不是红黑树中的节点
//表示此时下面挂的是链表
for ( int binCount = 0 ; ; ++ binCount ) {
if (( e = p . next ) == null ) {
//此时就会创建一个新的节点,挂在下面形成链表
p . next = newNode ( hash , key , value , null );
//判断当前链表长度是否超过8,如果超过8,就会调用方法treeifyBin
//treeifyBin方法的底层还会继续判断
//判断数组的长度是否大于等于64
//如果同时满足这两个条件,就会把这个链表转成红黑树
if ( binCount >= TREEIFY_THRESHOLD - 1 )
treeifyBin ( tab , hash );
break ;
}
//e: 0x0044 ddd 444
//要添加的元素: 0x0055 ddd 555
//如果哈希值一样,就会调用equals方法比较内部的属性值是否相同
if ( e . hash == hash && (( k = e . key ) == key || ( key != null && key . equals ( k )))){
break ;
}
p = e ;
}
}
//如果e为null,表示当前不需要覆盖任何元素
//如果e不为null,表示当前的键是一样的,值会被覆盖
//e:0x0044 ddd 555
//要添加的元素: 0x0055 ddd 555
if ( e != null ) {
V oldValue = e . value ;
if ( ! onlyIfAbsent || oldValue == null ){
//等号的右边:当前要添加的值
//等号的左边:0x0044的值
e . value = value ;
}
afterNodeAccess ( e );
return oldValue ;
}
}
//threshold:记录的就是数组的长度 * 0.75,哈希表的扩容时机 16 * 0.75 = 12
if ( ++ size > threshold ){
resize ();
}
//表示当前没有覆盖任何元素,返回null
return null ;
}
TreeMap源码分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
1 . TreeMap中每一个节点的内部属性
K key ; //键
V value ; //值
Entry < K , V > left ; //左子节点
Entry < K , V > right ; //右子节点
Entry < K , V > parent ; //父节点
boolean color ; //节点的颜色
2 . TreeMap类中中要知道的一些成员变量
public class TreeMap < K , V > {
//比较器对象
private final Comparator <? super K > comparator ;
//根节点
private transient Entry < K , V > root ;
//集合的长度
private transient int size = 0 ;
3 . 空参构造
//空参构造就是没有传递比较器对象
public TreeMap () {
comparator = null ;
}
4 . 带参构造
//带参构造就是传递了比较器对象。
public TreeMap ( Comparator <? super K > comparator ) {
this . comparator = comparator ;
}
5 . 添加元素
public V put ( K key , V value ) {
return put ( key , value , true );
}
参数一 : 键
参数二 : 值
参数三 : 当键重复的时候 , 是否需要覆盖值
true : 覆盖
false : 不覆盖
private V put ( K key , V value , boolean replaceOld ) {
//获取根节点的地址值,赋值给局部变量t
Entry < K , V > t = root ;
//判断根节点是否为null
//如果为null,表示当前是第一次添加,会把当前要添加的元素,当做根节点
//如果不为null,表示当前不是第一次添加,跳过这个判断继续执行下面的代码
if ( t == null ) {
//方法的底层,会创建一个Entry对象,把他当做根节点
addEntryToEmptyMap ( key , value );
//表示此时没有覆盖任何的元素
return null ;
}
//表示两个元素的键比较之后的结果
int cmp ;
//表示当前要添加节点的父节点
Entry < K , V > parent ;
//表示当前的比较规则
//如果我们是采取默认的自然排序,那么此时comparator记录的是null,cpr记录的也是null
//如果我们是采取比较去排序方式,那么此时comparator记录的是就是比较器
Comparator <? super K > cpr = comparator ;
//表示判断当前是否有比较器对象
//如果传递了比较器对象,就执行if里面的代码,此时以比较器的规则为准
//如果没有传递比较器对象,就执行else里面的代码,此时以自然排序的规则为准
if ( cpr != null ) {
do {
parent = t ;
cmp = cpr . compare ( key , t . key );
if ( cmp < 0 )
t = t . left ;
else if ( cmp > 0 )
t = t . right ;
else {
V oldValue = t . value ;
if ( replaceOld || oldValue == null ) {
t . value = value ;
}
return oldValue ;
}
} while ( t != null );
} else {
//把键进行强转,强转成Comparable类型的
//要求:键必须要实现Comparable接口,如果没有实现这个接口
//此时在强转的时候,就会报错。
Comparable <? super K > k = ( Comparable <? super K > ) key ;
do {
//把根节点当做当前节点的父节点
parent = t ;
//调用compareTo方法,比较根节点和当前要添加节点的大小关系
cmp = k . compareTo ( t . key );
if ( cmp < 0 )
//如果比较的结果为负数
//那么继续到根节点的左边去找
t = t . left ;
else if ( cmp > 0 )
//如果比较的结果为正数
//那么继续到根节点的右边去找
t = t . right ;
else {
//如果比较的结果为0,会覆盖
V oldValue = t . value ;
if ( replaceOld || oldValue == null ) {
t . value = value ;
}
return oldValue ;
}
} while ( t != null );
}
//就会把当前节点按照指定的规则进行添加
addEntry ( key , value , parent , cmp < 0 );
return null ;
}
private void addEntry ( K key , V value , Entry < K , V > parent , boolean addToLeft ) {
Entry < K , V > e = new Entry <> ( key , value , parent );
if ( addToLeft )
parent . left = e ;
else
parent . right = e ;
//添加完毕之后,需要按照红黑树的规则进行调整
fixAfterInsertion ( e );
size ++ ;
modCount ++ ;
}
private void fixAfterInsertion ( Entry < K , V > x ) {
//因为红黑树的节点默认就是红色的
x . color = RED ;
//按照红黑规则进行调整
//parentOf:获取x的父节点
//parentOf(parentOf(x)):获取x的爷爷节点
//leftOf:获取左子节点
while ( x != null && x != root && x . parent . color == RED ) {
//判断当前节点的父节点是爷爷节点的左子节点还是右子节点
//目的:为了获取当前节点的叔叔节点
if ( parentOf ( x ) == leftOf ( parentOf ( parentOf ( x )))) {
//表示当前节点的父节点是爷爷节点的左子节点
//那么下面就可以用rightOf获取到当前节点的叔叔节点
Entry < K , V > y = rightOf ( parentOf ( parentOf ( x )));
if ( colorOf ( y ) == RED ) {
//叔叔节点为红色的处理方案
//把父节点设置为黑色
setColor ( parentOf ( x ), BLACK );
//把叔叔节点设置为黑色
setColor ( y , BLACK );
//把爷爷节点设置为红色
setColor ( parentOf ( parentOf ( x )), RED );
//把爷爷节点设置为当前节点
x = parentOf ( parentOf ( x ));
} else {
//叔叔节点为黑色的处理方案
//表示判断当前节点是否为父节点的右子节点
if ( x == rightOf ( parentOf ( x ))) {
//表示当前节点是父节点的右子节点
x = parentOf ( x );
//左旋
rotateLeft ( x );
}
setColor ( parentOf ( x ), BLACK );
setColor ( parentOf ( parentOf ( x )), RED );
rotateRight ( parentOf ( parentOf ( x )));
}
} else {
//表示当前节点的父节点是爷爷节点的右子节点
//那么下面就可以用leftOf获取到当前节点的叔叔节点
Entry < K , V > y = leftOf ( parentOf ( parentOf ( x )));
if ( colorOf ( y ) == RED ) {
setColor ( parentOf ( x ), BLACK );
setColor ( y , BLACK );
setColor ( parentOf ( parentOf ( x )), RED );
x = parentOf ( parentOf ( x ));
} else {
if ( x == leftOf ( parentOf ( x ))) {
x = parentOf ( x );
rotateRight ( x );
}
setColor ( parentOf ( x ), BLACK );
setColor ( parentOf ( parentOf ( x )), RED );
rotateLeft ( parentOf ( parentOf ( x )));
}
}
}
//把根节点设置为黑色
root . color = BLACK ;
}
双列集合小结
JDK5提出的特性。方法形参的个数是可以发生变化的。格式:属性类型…名字。举例:int…args
底层原理:可变参数底层就是一个数组,只不过不需要自己创建,java底层会自动创建。
可变参数细节:方法的形参中最多只能写一个可变参数。在方法中除了可变参数之外还有其他形参,那么可变参数要写在最后。
Collections介绍
java.util.Collections是集合工具类 作用:collections不是集合,而是集合的工具类 Collections常用API
方法名称 说明 public static < T > boolean addAll(Collection< T > c, T…elements) 批量添加元素 public static void shuffle(List list) 打乱List集合元素的顺序
不可变集合介绍
不可变集合:不可以被修改的集合。
创建不可变集合的应用场景
如果某个数据不能被修改,把他防御性地拷贝到不可变集合是个很好的实践。 当集合被不可信的库调用时,不可变形式是安全的。 创建不可变集合的书写格式
在List、Map、Set集合中,都存在静态的of方法,可以获取一个不可变的集合。
方法名称 说明 static < E > List< E > of(E…elements) 创建一个具有指定元素的List集合对象 static < E > Set< E > of(E…elements) 创建一个具有指定元素的Set集合对象 static <K, V> Map<K, V> of(E…elements) 创建一个具有指定元素的Map集合对象
Stream流的作用
结合Lambda表达式,简化集合、数组的操作。
Stream流的使用步骤
先得到一条Stream流,并把数据放上去。 利用Stream流中的API进行各种操作。中间方法:调用完毕之后,还可以调用其他方法。(过滤、转换) 终结方法:最后一步,调用完毕之后,不能调用其他方法。(统计、打印) 获取Stream流方式
获取方式 方法名 说明 单列集合 default Stream< E > stream() Collection类中的默认方法 双列集合 无 无法直接使用Stream流 数组 public static < T > Stream< T > stream(T[] array) Arrays工具类中的静态方法 一堆零散数据 public static < T > Stream< T > stream(T…values) Stream接口中的静态方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
//1.单列集合获取Stream流
ArrayList < String > list = new ArrayList <> ();
Collections . addAll ( list , "a" , "b" , "c" , "d" , "e" );
//获取一条流水线,并把集合中的数据放到流水线上
Stream < String > stream1 = list . stream ();
//使用终结方法打印流水线上所有数据
stream1 . forEach ( new Consumer < String > () {
@Override
public void accept ( String s ) {
//s表示流水线上的每一个数据
System . out . println ( s );
}
});
//链式编程结合Lambda表达式
//list.stream().forEach(s -> System.out.println(s));
1
2
3
4
5
6
7
8
9
10
11
//1.创建双列集合
HashMap < String , Integer > hm = new HashMap <> ();
//2.添加数据
hm . put ( "aaa" , 111 );
hm . put ( "bbb" , 222 );
hm . put ( "ccc" , 333 );
hm . put ( "ddd" , 444 );
//3.第一种方法获取Stream流
hm . keySet (). stream (). forEach ( s -> System . out . println ( s ));
//4.第二种方法获取Stream流
hm . entrySet (). stream (). forEach ( s -> System . out . println ( s ))
1
2
3
4
//1.创建数据
int [] arr = { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 };
//2.获取stream流
Arrays . strem ( arr ). forEach ( s -> System . out . println ( s ));
1
2
3
4
//零散数据
//方法形参是一个可变参数,可以传递一堆零散的数据,也可以传递数组
//但是数组必须是引用数据类型的,如果传递基本数据类型,是会把整个数组当作一个元素放入stream中。
stream . of ( 1 , 2 , 3 , 4 , 5 ). forEach ( s -> System . out . println ( s ));
Stream流的中间方法
名称 说明 Stream< T > filter(Predicate<? super T> predicate) 过滤 Stream< T > limit(long maxSize) 获取前几个元素 Stream< T > skip(long n) 跳过前几个元素 Stream< T > distinct() 元素去重,依赖(HashCode()和equals方法) static< T >Stream< T > concat(Stream a, Stream b) 合并a和b两个流为一个流 Stream< R > map(Function<T, R> mapper) 转换流中的数据类型
注意点:
中间方法,返回新的stream流,原来的stream流只能用一次,建议使用链式编程。 修改stream流中的数据,不会影响原来集合或者数组中的数据。 Stream流的终结方法
名称 说明 void forEach(Consumer action) 遍历 long count() 统计 toArray() 收集流中的数据,放到数组中 collect(Collector collector) 收集流中的数据,放到集合中
方法引用概述
方法引用:把已经有的方法拿过来使用,当作函数式接口中抽象方法的方法体。
1
2
3
4
5
6
7
8
9
//引用处必须是函数式接口
Arrays . sort ( arr , 比较规则 );
//已经存在的方法
//被引用的方法必须已经存在
//被引用的方法的形参和返回值需要跟抽象方法保持一致
//被引用的方法的功能需要满足当前要求
public int substraction ( int n1 , int n2 ) {
return n2 - n1 ;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
//需求:创建一个数组,进行倒序排序
Integer [] arr = { 3 , 4 , 5 , 1 , 6 , 23 }
//匿名内部类
Arrays . sort ( arr , new Comparator < Integer > () {
@Override
pubilc int compare ( Integer o1 , Integer o2 ) {
return o2 - o1 ;
}
});
//Lambda表达式
Arrays . sort ( arr , ( Integer o1 , Integer o2 ) -> {
return o2 - o1 ;
});
//Lambda表达式简化形式
Arrays . sort ( arr , ( o1 , o2 ) -> o2 - o1 );
//方法引用
Arrays . sort ( arr , 类名 :: substraction );
//可以是java写好的代码,也可以是一些第三方工具
public static int substraction ( int n1 , int n2 ) {
return n2 - n1 ;
}
方法引用的分类
引用静态方法 引用成员方法引用其他类的成员方法 引用本类的成员方法 引用父类的成员方法 引用构造方法 其他调用方式 引用静态方法
格式:类名::静态方法
示例:Integer::parseInt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
/*
*需求:把集合中的数据变成int类型。
**/
//1.创建集合并添加元素
ArrayList < String > list = new ArrayList <> ();
Collections . addAll ( arr , "1" , "2" , "3" , "4" , "5" );
//2.变成int类型
list . stream (). map ( new Function < String , Integer > () {
@Override
public Integer apply ( String s ) {
int i = Integer . parseInt ( s )
return i ;
}
}). forEach ( s -> System . out . println ( s ));
list . stream (). map ( Integer :: parseInt ). forEach ( s -> System . out . println ( s ));
引用成员方法
格式:对象::成员方法
其他类:其他类对象::方法名 本类:this::方法名 父类:super::方法名 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
/*
*需求:按一定的要求过滤数据
**/
//1.创建集合并添加元素
ArrayList < String > list = new ArrayList <> ();
Collections . addAll ( arr , "张三三" , "张四" , "李四" , "张五" , "李六" );
//2.lambda
list . stream ()
. filter ( s -> s . startwith ( "张" )). filter ( s -> s . length () == 3 )
. forEach ( s -> System . out . println ( s ));
//匿名内部类
list . stream (). filter ( new Predicate < String > () {
@Override
public boolean test ( String s ) {
return s . startwith ( "张" ) && s . length () == 3 ;
}
});
//引用成员方法
list . stream (). filter ( new StringOpreation ():: stringJudge );
public class StringOperation {
public boolean stringJudge ( String s ) {
return s . startwith ( "张" ) && s . length () == 3 ;
}
}
引用构造方法
格式:类名::new
返利:Student::new
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
/*
*需求:集合存储姓名和年龄,要求封装成Student对象并收集到List集合中
**/
//1.创建集合并添加元素
ArrayList < String > list = new ArrayList <> ();
Collections . addAll ( arr , "张三三,23" , "张四,25" , "李四,26" , "张五,27" , "李六,28" );
//2.封装成Student对象并收集到List集合中
List < Student > list = list . stream (). map ( new Function < String , Student > () { //此处Student类已经提前定义好
@Override
public Student apply ( String s ) {
String name = s . split ( "," ) [ 0 ] ;
int age = Integer . parseInt ( s . split ( "," ) [ 1 ] );
return new Student ( name , age );
}
}). collect ( Collections . toList ());
list . stream (), map ( Student :: new ); //此时要在student类中完善构造方法
使用类名引用成员方法
格式:类名::成员方法
范例:String::substring
方法引用的规则(独有):
需要有函数式接口 被引用的方法必须已经存在 被引用方法的形参需要和抽象方法的第二个形参到最后一个形参保持一致,返回值需要保持一致 被引用方法的功能需要满足当前的需求 抽象方法形参详解:
第一个参数:表示被引用方法的调用者,决定了可以引用哪些类中的方法。在stream流中,第一个参数一般都表示流里面每一个元素。假设流里面的数据都是字符串,那么使用这种方式进行方法引用,只能引用String这个类中的方法。 第二个参数到最后一个参数:跟被引用方法的形参保持一致,如果没有第二个参数,说明被引用的方法需要是无参的成员方法。 局限性:不能引用所有类中的成员方法,跟抽象方法的第一个参数有关,这个参数是什么类型的,那么就只能引用这个类中的方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
/*
*需求:将集合中的元素转成大写后输出
**/
//1.创建集合并添加元素
ArrayList < String > list = new ArrayList <> ();
Collections . addAll ( arr , "aaa" , "bbb" , "ccc" , "ddd" );
//2.变成大写后输出
list . stream (). map ( new Function < String , String > () {
@Override
public String apply ( String s ) {
return s . toUpperCase ();
}
}). forEach ( s -> System . out . println ( s ));
//3.改写成方法引用
//拿着流里面的每一数组调用toUpperCase方法,方法的返回值就是转换之后的结果。
list , stream (). map ( String :: toUpperCase ). forEach ( s -> System . out . println ( s ));
引用数组的构造方法
格式:数据类型[]::new
范例:int[]::new
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
/*
*需求:集合中存储一些整数,收集到数组当中
**/
//1.创建集合并添加元素
ArrayList < Integer > list = new ArrayList <> ();
Collections . addAll ( arr , 1 , 2 , 3 , 4 , 5 );
//2.收集到数组当中
Integer [] arr = list . stream (). toArray ( new IntFunction < Integer []> () {
@Override
public Integer [] apply ( int value ) {
return new Integer [ value ] ;
}
});
//3.改写成方法引用
//数组的类型要和流中数据的类型保持一致。
Integer [] arr = list . stream (). toArray ( Integer [] :: new );
异常概述
异常:异常就是代表程序出现的问题。
误区:不是不出异常,而是程序出异常该如何处理。
异常体系结构
1
2
3
4
5
6
7
8
9
10
//编译时异常,必须手动处理,否则代码报错
public static void main ( String [] args ) throws ParseException {
String time = "2030年10月20日" ;
SimpleDateFormat sdf = new SimpleDateFormat ( "yyyy年MM月dd日" );
Data data = sdf . parse ( time );
System . out . println ( data );
}
//运行时异常
int [] arr = { 1 , 2 , 3 , 4 , 5 };
System . out . println ( arr [ 10 ] );
异常分类
异常的作用
异常是用来查询bug的关键参考信息 异常可以作为方法内部的一种特殊返回值,以便通知调用者底层的执行情况 异常的处理方式
JVM默认的处理方案(如果没有写任何处理方案,代码会交给虚拟机进行处理) 自己处理 抛出异常 JVM默认处理方案
把异常的名称、原因及异常出现的位置等信息输出控制台 程序停止执行,下面的代码不再执行 自己处理(捕获异常)
格式:
1
2
3
4
5
try {
可能出现异常的代码 ;
} catch ( 异常类名 变量名 ) {
异常处理的代码 ;
}
目的:当代码出现异常时,可以让程序继续往下执行。
1
2
3
4
5
6
7
8
9
10
11
12
int [] arr = { 1 , 2 , 3 };
try {
System . out . println ( arr [ 3 ] ); //此处出现了异常,程序会再次创建一个ArrayIndexOutOfBoundsException对象
//拿这该对象到catch的小括号中进行对比,看括号中的变量是否可以接收这个对象
//如果能接收,就表示该异常被捕获,执行catch里面对应的代码
//当catch里面的所有代码执行完毕,继续执行try...catch体系下面的其他代码
} catch ( ArrayIndexOutOfBoundsException e ) {
//处理方法
System . out . println ( "越界" );
}
//后续代码可以执行
-----------------
几个问题
Throwable的成员方法
方法名称 说明 public String getMessage() 返回此throwable的详细消息字符串 public String toString() 返回此可抛出的简短描述 public void printStackTrace() 将异常的错误信息输出在控制台
1
2
3
4
5
6
7
8
9
int [] arr = { 1 , 2 , 3 };
try {
System . out . println ( arr [ 3 ] );
} catch ( ArrayIndexOutOfBoundsException e ) {
//处理方法
String message = e . getMessage ();
System . out . println ( message );
}
//e.printStackTrace仅仅打印信息,不会停止程序运行。
抛出处理throws
注意:写在方法定义处,表示申明一个异常,告诉调用者,使用本方法可能会有哪些异常。
1
2
3
public void 方法 () trhows 异常名1 , 异常名2 ...{
...
}
编译时异常必须写,运行时异常可以不写。
抛出处理throw
注意:写在方法内,表示结束方法。手动抛出异常对象,交给调用者,方法中下面的代码不再执行。
1
2
3
public void 方法 (){
throw new NullPointerException (); //方法中下面的代码不再执行
}
自定义异常
1
2
3
4
5
6
7
8
9
10
11
12
13
public class nameFormatException extends RuntimeException {
//nameFormat:当前类的名字,表示姓名格式化问题
//Exception:表示当前是一个异常类
//运行时异常继承:RuntimeException
//编译时异常:Exception
public NameFormatException (){
}
public NameFormatException ( String message ){
super ( message );
}
}
File概述
File对象表示一个路径,可以是文件的路径、也可以是文件夹的路径。 这个路径可以是存在的,也允许是不存在的。 File构造方法
方法名称 说明 public File(String pathname) 根据文件路径创建文件对象 public File(String parent, String child) 根据父路径字符串和子路径名字符串创建文件对象 public File(File parent, String child) 根据父路径对应文件对象和子路径名字符串创建文件对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//1.根据字符串表示的路径,变成File对象
String str = "D:\\NewFile\\a.txt" ;
File f1 = new File ( str );
System . out . println ( f1 );
//2.根据父路径字符串和子路径名字符串创建文件对象
//父级路径:D:\\NewFile
//子集路径:a.txt
String parent = "D:\\NewFile" ;
String child = "a.txt" ;
File f2 = new File ( parent , child );
//3.把File表示的路径和String表示的路径进行拼接
File f3 = new File ( "D:\\NewFile" );
String child2 = "a.txt" ;
File f4 = new file ( parent , child2 );
File常见成员方法(判断、获取)
方法名称 说明 public boolean isDirectory() 判断此路径名表示的File是否为文件夹 public boolean isFile() 判断此路径表示的File是否为文件 public boolean exists() 判断此路径名表示的File是否存在 public long length() 返回文件的大小(字节数量)==无法获取文件夹大小== public String getAbsolutePath() 返回文件的绝对路径 public String getName() 返回文件的名称,带后缀 public String getPath() 返回文件定义时使用的路径 public long lastModified() 返回文件的最后修改时间(时间毫秒值)
File成员方法(创建、删除)
方法名称 说明 public boolean createNewFile() 创建一个空的文件 public boolean mkdir() 创建单级文件夹 public boolean mkdirs() 创建多级文件夹 public boolean delete() 删除文件、空文件夹
createNewFile()细节:
如果文件不存在则创建成功,否则失败 如果父级路径不存在,那么方法会有异常IOException createNewFile创建的一定是文件,如果路径中不包含后缀名,则创建一个没有后缀的文件 delete细节
如果删除的文件是文件则直接删除,不走回收站 如果删除的是空文件夹,则直接删除,不走回收站 如果删除的是有内容的文件夹,则删除失败 File成员方法(获取并遍历)
方法名称 说明 public File[] listFiles() 获取当前该路径下所有内容 public static File[] listRoots() 列出可用的文件系统根(获取系统中的所有盘符) public String[] list() 获取当前路径下的所有内容 public String[] list(FileNameFilter filter) 利用文件名过滤器获取当前该路径下的所有内容 public File[] listFiles(FileFilter filter) 利用文件名过滤器获取当前该路径下的所有内容 public File[] listFiles(FileNameFilter filter) 利用文件名过滤器获取当前该路径下的所有内容
1
2
3
4
5
6
7
8
//1.创建File对象
File f = new File ( "D:\\NewFile" );
//2.ListFiles方法
//作用:获取aaa文件夹里面所有内容,把内容放到数组中返回
File [] files = f . listFiles ();
for ( File file : files ) {
//file依次表示文件夹里面的每一个文件或者文件夹
}
当调用者File表示的路径不存在时,返回null 当调用者File表示的路径是文件是,返回null 当调用者File表示的路径是一个空文件夹时,返回一个长度为0的数组 当调用者File表示的是一个有内容的文件夹时,将里面所有文件和文件夹的路径放在File数组返回 当调用者File表示的路径是需要权限才能访问的文件夹时,返回null io流概述
IO流:存储和读取数据的解决方案。用于读写文件中的数据(可以读写文件、或网络中的数据)
File:表示系统中文件或者文件夹的路径。
注意:File类只能对文件本身进行操作,不能读写文件里面存储的数据。
IO流中以程序作为参照物看读写的方向。
IO流的分类
IO流的分类
IO流的体系
IO流体系结构
字节流体系结构
FileOutputStream
作用:操作本地文件的字节输出流,可以把程序中的数据写到本地文件中。
书写步骤:
创建字节输出流对象 写数据 释放资源 1
2
3
4
5
6
7
8
9
10
11
12
13
14
/*
*需求:写一段文字到本地文件中。
**/
//1.创建对象
//细节1:参数是字符串表示的路径或者File对象
//细节2:如果文件不存在会创建一个新的文件,但要保证父级路径是存在的
//细节3:如果文件已经存在,则会清空文件
FileOutputStream fos = new FileOutputStream ( "thisProject\\a.txt" ); //需要指定文件路径
//2.写出数据
//细节:write方法的参数是整数,但是实际上写到本地文件中的是整数在ASCII上对应的字符
fos . write ( 97 );
//3.释放资源
//每次使用完流之后都要释放资源
fos . close (); //'a'
FileOutputStream写数据的3种方式
方法名称 说明 void write(int b) 一次写一个字节数据 void write(byte[] b) 一次写一个字节数组数据 void write(byte[] b, int off, int len) 一次写一个字节数组的部分数据
1
2
3
4
5
6
7
8
9
10
11
/*
*需求:写一段文字到本地文件中。
**/
//1.创建对象
FileOutputStream fos = new FileOutputStream ( "thisProject\\a.txt" ); //需要指定文件路径
//2.写出数据
byte [] bytes = { 97 , 98 , 99 }
//fos.write(bytes);
fos . write ( bytes , 1 , 2 );
//3.释放资源
fos . close (); //"abc" "bc"
FileOutputStream换行与续写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
/*
*需求:换行。
**/
//1.创建对象
FileOutputStream fos = new FileOutputStream ( "thisProject\\a.txt" ); //需要指定文件路径
//2.写出数据
String str1 = "wenben"
byte [] bytes1 = str1 . getBytes ();
fos . write ( bytes1 );
//换行操作
String wrap = "\r\n" ;
byte [] bytes = str1 . getBytes ();
fos . write ( bytes );
String str2 = "xuxie"
byte [] bytes2 = str2 . getBytes ();
fos . write ( bytes2 );
//3.释放资源
fos . close (); //"abc" "bc"
1
2
3
4
5
6
7
8
9
10
11
/*
*需求:续写。
**/
//1.创建对象
FileOutputStream fos = new FileOutputStream ( "thisProject\\a.txt" , true ); //打开续写开关
//2.写出数据
String str = "wenben"
byte [] bytes = str1 . getBytes ();
fos . write ( bytes );
//3.释放资源
fos . close (); //"abc" "bc"
FileInputStream
作用:操作本地文件的字节输出流,可以把本地文件中的数据读取到程序中来。
书写步骤:
创建字节输入流对象 读数据 释放资源 1
2
3
4
5
6
7
8
9
10
11
12
13
/*
*需求:读文件到程序中。
**/
//1.创建对象
//细节1:文件不存在直接报错
FileInputStream fis = new FileInputStream ( "thisProject\\a.txt" ); //需要指定文件路径
//2.读取数据
//细节:一次读一个字节,读出来的是数据在ASCII上对应的数字
//细节:读到末尾了,read方法返回-1
int b1 = fis . read ();
//3.释放资源
//每次使用完流之后都要释放资源
fis . close ();
FileInputStream循环读取
1
2
3
4
5
6
7
8
9
10
11
12
/*
*需求:循环读取。
**/
//1.创建对象
FileInputStream fis = new FileInputStream ( "thisProject\\a.txt" ); //需要指定文件路径
//2.读取数据
int b ; //read每读取一次就移动一次指针
while (( b = fis . read ()) != - 1 ) {
System . out . println ( char ( b ));
}
//3.释放资源
fis . close ();
FileInputStream一次读取多个字节
方法名称 说明 public int read() 一次读一个字节数据 public int read(byte[] buffer) 一次读一个字节数组数据
1
2
3
4
5
6
7
8
9
10
11
/*
*需求:一次读取多个数组
**/
//1.创建对象
FileInputStream fis = new FileInputStream ( "thisProject\\a.txt" ); //需要指定文件路径
//2.读取数据
byte [] bytes = new byte [ 2 ] ;
int len = fis . read ( bytes );
String str = new String ( bytes , 0 , len );
//3.释放资源
fis . close ();
try…catch异常处理
1
2
3
4
5
6
7
8
try {
FileOutputStream fos = new FileOutputStream ( "thisProject\\a.txt" ); //需要指定文件路径
fos . write ( 97 );
} catch ( IOException e ){
e . printStackTrace ();
} finally {
fos . close (); //被finally控制的语句一定会执行,除非jvm退出
}
1
2
3
4
5
6
7
//JDK7中IO流捕获异常的方法
//注意:只有实现了AutoCloseable接口的类,才能在小括号中创建对象。
try ( FileOutputStream fos = new FileOutputStream ( "thisProject\\a.txt" )) {
fos . write ( 97 );
} catch ( IOException e ) {
e . printStackTrace ();
} //资源用完自动释放
1
2
3
4
5
6
7
//JDK9中IO流捕获异常的方法
FileOutputStream fos = new FileOutputStream ( "thisProject\\a.txt" );
try ( fos ) {
fos . write ( 97 );
} catch ( IOException e ) {
e . printStackTrace ();
} //资源用完自动释放
字符集
ASCII字符集一个英文占一个字节,编码时最高位补0.
GBK字符集完全兼容ASCII字符集,一个英文占一个字节,二进制第一位是0.一个中文占两个字节,二进制高位字节第一位是1.
UTF-8编码标准:用1~4个字节保存。ASCII用一个字节表示,简体中文3个字节表示。中文第一个字节首位是1.
编码规则:将查到的8位二进制数字填入1110xxxx-10xxxxxx-10xxxxxx
为什么会有乱码?
原因1:读取数据时未读完整个汉字。 原因2:编码和解码的方式不统一。 解决乱码的方法
不要使用字节流读取文本文件。 编码解码时使用同一个码表,同一个编码方式。 Java中编码的方式
String类中的方法 说明 public byte[] getBytes() 使用默认方式进行编码 public byte[] getBytes(String charsetName) 使用指定方式进行编码
Java中解码的方式
String类中的方法 说明 String(byte[] bytes) 使用默认方式进行解码 String(byte[] bytes, String charsetName) 使用指定方式进行解码
字符流
字符流:字符类底层其实就是字节流。
特点
输入流:一次读一个字节,遇到中文时,一次读多个字节。 输出流:底层会把数据按照指定的编码方式进行编码,变成字节再写到文件中。 使用场景:对于纯文本文件进行读写操作。
FileReader
与字节流方法大致相同,不同点是遇到中文一次读取多个字节。
1
2
3
4
5
6
7
8
9
10
11
12
//1.创建对象并关联本地文件
FileReader fr = new FileReader ( "thisProject\\a.txt" );
//2.读取数据
//底层也是字节流,默认一个一个字节读取
//如果遇到中文则一次读取多个,GBK一次读两个字节,UTF-8一次读三个字节。
//读取之后会把十进制作为返回值,十进制数据表示字符集上的字符
int ch ;
while (( ch = fr . read ()) != - 1 ) {
System . out . print (( char ) ch );
}
//3.关流
fr . close ();
FileWriter
构造方法 说明 public FileWriter(File file) 创建字符输出流关联本地文件 public FileWriter(String pathname) 创建字符输出流关联本地文件 public FileWriter(File file, boolean append) 创建字符输出流关联本地文件,续写 public FileWriter(String pathname, boolean append) 创建字符输出流关联本地文件,续写
FileWriter成员方法
成员方法 说明 void write(int c) 写出一个字符 void write(String str) 写出一个字符串 void write(String str, int off, int len) 写出一个字符串的一部分 void write(char[] chuf) 写出一个字符数组 void write(char[] chuf, int off, int len) 写出一个字符数组的一部分
细节:如果write方法的参数是整数,但是实际上写到本地文件的是整数在字符集上对应的字符。
字符输入流底层原理分析
创建字符输入流对象底层:关联文件,并创建缓冲区(长度为8192的字节数组) 读取数据判断缓冲区是否有数据可以读取 缓冲区没有数据就从文件中获取数据,装到缓冲区中,每次尽可能装满缓冲区,如果文件中没有数据了,返回-1 缓冲区有数据:就从缓冲区读取。空参read方法一次读取一个字节,遇到中文则读取多个字节,把字节解码并转成十进制返回。有参read方法:把读取字节、解码、强转合并。强转之后的字符放到数组中。 字符输出流底层原理分析
缓冲区往文件写数据的三种情况:
情况一:缓冲区装满 情况二:flush操作 情况三:关流 flush与close方法
成员方法 说明 public void flush() 将缓冲区的数据,刷新到本地文件中 public void close() 释放资源/关流
flush刷新:刷新之后,还可以继续往文件中写出数据。
close关流:断开通道,无法再往文件中写出数据。
字节流与字符类的使用场景
字节流:可以拷贝任意类型的文件。
字符流:读取或者写入纯文本文件中的数据。
递归遍历文件夹
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
//1.创建对象表示数据源与目的地
File src = new File ( "D:\\source" );
File des = new File ( "D:\\destiny" );
//2.调用方法拷贝
copyDir ( src , des );
/*
*作用:拷贝文件夹
**/
private static void copyDir ( File src , File des ) {
des . mkdirs ();
//1.进入数据源
File [] files = src . listFiles ();
//2.遍历数组
for ( File file : files ) {
if ( file . isFile ()) {
//3.若为文件则拷贝
FileInputStream fis = new FileInputStream ( file );
FileOutputStream fos = new FileOutputStream ( new File ( des , file . getName ())); //从文件到文件
byte [] bytes = new byte [ 1024 ] ;
int len ;
while (( len = fis . read ( bytes )) != - 1 ) {
fos . write ( bytes , 0 , len );
}
//关流,先开的后关
fos . close ();
fis . close ();
} else {
//4.若为文件夹则递归
copyDir ( file , new File ( des , file . getName ()));
}
}
}
缓冲流体系结构
缓冲流体系结构
字节缓冲流
原理:底层自带了长度为8192的缓冲区提高性能
方法名称 说明 public BufferedInputStream(InputStream is) 把基本流包装成高级流,提高读取数据的性能 public BufferedOutputStream(OutputStream os) 把基本流包装成高级流,提高写出数据的性能
1
2
3
4
5
6
7
8
9
10
11
//1.创建缓冲流对象
BufferedInputStream bis = new BufferedInputStream ( new FileInputStream ( "thisProject\\a.txt" ));
BufferedOutputStream bos = new BufferedOutputStream ( new FileOutputStream ( "thisProject\\a_copy.txt" ));
//2.循环读取并写到目的地
int b ;
while (( b = bis . read ()) != - 1 ) {
bos . write ( b );
}
//3.释放资源
bos . close ();
bis . close ();
字节缓冲流原理
字节缓冲流原理
字符缓冲流
原理:底层自带了长度为8192的缓冲区提高性能
方法名称 说明 public BufferedReader(Reader r) 把基本流变成高级流 public BufferedWriter(Writer r) 把基本流变成高级流
特有方法:
字符缓冲输入流特有方法 说明 public String readLine() 读一行数据,如果没有数据可读了,会返回null
字符缓冲输出流特有方法 说明 public void newLine() 跨平台的换行
1
2
3
4
5
6
7
8
//1.创建字符缓冲输入流的对象
BufferedReader br = new BufferedReader ( new FileReader ( "thisProject\\a.txt" ));
//2.读取数据
//readLine方法一次读一整行,遇到回车换行符结束,但不会把回车读入到内存中
String line = br . readLine ();
System . out . println ( line );
//3.关流
br . close ();
转换流是字符流和字节流之间的桥梁。
转换流在IO流中的位置
转换流示意图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
/*
*利用转换流按照指定字符编码进行读取
*/
//已淘汰
//1.创建对象并指定字符编码
InputStreamReader isr = new InputStreamReader ( new FileInputStream ( "sample.txt" ), "GBK" );
//2.读取数据
int ch ;
while (( ch = isr . read ()) != - 1 ) {
System . out . print (( char ) ch );
}
//3.释放资源
isr . close ();
//替代方法 SINCE JDK11
FileReader fr = new FileReader ( "sample.txt" , Charset . forName ( "GBK" ));
1
2
3
4
5
6
7
8
9
10
/*
*字节流使用字符流中的方法
*/
//创建字节流
FileInputStream fis = new FileInputStream ( "sample.txt" );
//包装字节流成字符流
InputStreamReader isr = new InputStreamReader ( fis );
//包装成缓冲流
BufferedReader fr = new BufferedReader ( isr );
//之后便可以调用缓冲流中的方法
序列化流
序列化流可以把Java中的对象写到本地文件中。
序列化流在IO流中的位置
构造方法 说明 public ObjectOutputStream(OutputStream out) 把基本流包装成高级流
成员方法 说明 public final void writeObject(Object obj) 把对象序列化写出到文件中去
1
2
3
4
5
6
7
8
9
10
11
12
13
/*
* 需求:把一个对象写到文件中
*/
//1.创建对象
Student stu = new Student ( "zhangsan" , 23 );
//2.创建序列化流的对象
ObjectOutputStream oos = new ObjectOutputStream ( new FileOutputStream ( "sample.txt" ));
//3.写出数据
oos . writeObject ( stu );
//4.释放资源
oos . close ();
//细节:需要让JavaBean类实现serializable接口
//serializable接口没有抽象方法,为标记型接口
反序列化流/对象操作输入流
反序列化流可以把序列化到本地文件中的对象读取到程序中来。
构造方法 说明 public ObjectIntputStream(InputStream out) 把基本流包装成高级流
成员方法 说明 public Object readObject() 把序列化到本地文件中的对象读取到程序中来
1
2
3
4
5
6
7
8
9
10
11
/*
* 需求:把序列化到本地文件中的对象读取到程序中来
*/
//1.创建反序列化流的对象
ObjectInputStream ois = new ObjectInputStream ( new FileInputStream ( "sample.txt" ));
//2.读出数据
Object o = ois . readObject ();
//3.打印对象
System . out . prinln ( o );
//4.释放资源
ois . close ();
序列化流/反序列化流的细节汇总
使用序列化流将对象写到文件时,需要让lavabean类实现Serializable接口否则,会出现NotSerializableException异常 序列化流写到文件中的数据是不能修改的,一旦修改就无法再次读回来了 序列化对象后,修改了Javabean类,再次反序列化,会不会有问题?会出问题,会抛出InvalidClassException异常解决方案:给javabean类添加serialVersionUID(序列号、版本号) 如果一个对象中的某个成员变量的值不想被序列化,又该如何实现呢?解决方案:给该成员变量加transient关键字修饰,该关键字标记的成员变量不参与序列化过程 分类:打印流一般指:PrintStream,PrintWrite两个类
特点:
打印流只操作文件目的地,不操作数据源(只能写,不能读) 特有的写出方法可以实现,数据原样写出 特有的写出方法,可以实现自动刷新,自动换行 打印流在IO流中的位置
字节打印流
构造方法 说明 public PrintSream(OutputStream/File/String) 关联字节输出流/文件/文件路径 public PrintSream(String fileName, Charset charset) 指定字符编码 public PrintSream(OutputStream out, boolean autoFlush) 自动刷新 public PrintSream(OutputStream out, boolean autoFlush,String encoding) 指定字符编码并自动刷新
字节流底层没有缓冲区,开不开自动刷新都一样。
成员方法 说明 public void write(int b) 常规方法:规则跟之前一样,将指定的字节写出 public void println(Xxx xx) 特有方法:打印任何数据,自动刷新,自动换行 public void print(Xxx xx) 特有方法:打印任何数据,不换行 public void printf(String format, Object … args) 特有方法:带有占位符的打印语句,不换行
1
2
3
4
5
6
//1.创建字节打印流
PrintStream ps = new PrintStream ( new FileOutputStream ( "b.txt" ), true , "GBK" );
//2.写出数据
ps . println ( 97 );
//3.释放资源
ps . close (); //写入"97"
字符打印流
构造方法 说明 public PrintWriter(OutputStream/File/String) 关联字节输出流/文件/文件路径 public PrintWriter(String fileName, Charset charset) 指定字符编码 public PrintWriter(OutputStream out, boolean autoFlush) 自动刷新 public PrintWriter(OutputStream out, boolean autoFlush,String encoding) 指定字符编码并自动刷新
字符流底层有缓冲区,想要自动刷新需要开启。
成员方法 说明 public void writer(int b) 常规方法:规则跟之前一样,将指定的字节写出 public void println(Xxx xx) 特有方法:打印任何数据,自动刷新,自动换行 public void print(Xxx xx) 特有方法:打印任何数据,不换行 public void printf(String format, Object … args) 特有方法:带有占位符的打印语句,不换行
1
2
3
4
5
6
//1.创建字节打印流
PrintWriter pw = new PrintWriter ( new FileWriter ( "b.txt" ), true );
//2.写出数据
pw . println ( 97 );
//3.释放资源
pw . close (); //写入"97"
打印流的应用场景
1
2
3
4
//获取打印流对象,此打印流在虚拟机启动的时候,由虚拟机创建,默认指向控制台。
//特殊打印流,系统中的标准输出流,不能关闭,在系统中是唯一的。
PrintStream ps = System . out ;
ps . println ( "123" );
压缩流在IO流中的位置
解压缩流
解压本质:压缩包里面每一个文件都是ZipEntry对象。把每一个ZipEntr y按照层级拷贝到本地另一个文件夹中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
public class Demo {
public static void main ( String [] args ) throws IOException {
//1.创建一个file表示要解压的压缩包
File src = new File ( "sample.zip" );
//2.创建一个file表示解压的目的地
File dest = new File ( "sampleTo" );
//3.调用方法
unZip ( src , dest );
}
//定义一个方法用来解压
public static void unZip ( File src , File dest ) throws IOException {
//创建一个解压缩流来读取压缩包中的数据
ZipInputStream zip = new ZipInputStream ( new FileInputStream ( src ));
//获取到压缩包内的每一个zipEntry对象
ZipEntry entry ;
while (( entry = zip . getNextEntry ()) != null ) {
//文件夹:在目的地创建一个同样的文件夹
if ( entry . isDirectory ()) {
File file = new File ( dest , entry . toString ());
file . mkdirs ();
} else {
//文件:存到dest目标文件夹中
FileOutputStream fos = new FileOutputStream ( dest );
int b ;
while (( b = zip . read ()) != - 1 ) {
fos . write ( b );
}
fos . close ();
//表示在压缩包里面的一个文件处理完毕了
zip . closeEntry ();
}
}
zip . close ();
}
}
压缩流
压缩本质:把每一个文件/文件夹看成ZipEntry对象放到压缩包中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
public class ZipStreamDemo2 {
public static void main ( String [] args ) throws IOException {
/*
* 压缩流
* 需求:
* 把D:\\a.txt打包成一个压缩包
* */
//1.创建File对象表示要压缩的文件
File src = new File ( "D:\\a.txt" );
//2.创建File对象表示压缩包的位置
File dest = new File ( "D:\\" );
//3.调用方法用来压缩
toZip ( src , dest );
}
/*
* 作用:压缩
* 参数一:表示要压缩的文件
* 参数二:表示压缩包的位置
* */
public static void toZip ( File src , File dest ) throws IOException {
//1.创建压缩流关联压缩包
ZipOutputStream zos = new ZipOutputStream ( new FileOutputStream ( new File ( dest , "a.zip" )));
//2.创建ZipEntry对象,表示压缩包里面的每一个文件和文件夹
//参数:压缩包里面的路径
ZipEntry entry = new ZipEntry ( "aaa\\bbb\\a.txt" );
//3.把ZipEntry对象放到压缩包当中
zos . putNextEntry ( entry );
//4.把src文件中的数据写到压缩包当中
FileInputStream fis = new FileInputStream ( src );
int b ;
while (( b = fis . read ()) != - 1 ){
zos . write ( b );
}
zos . closeEntry ();
zos . close ();
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
public class ZipStreamDemo3 {
public static void main ( String [] args ) throws IOException {
/*
* 压缩流
* 需求:
* 把D:\\aaa文件夹压缩成一个压缩包
* */
//1.创建File对象表示要压缩的文件夹
File src = new File ( "D:\\aaa" );
//2.创建File对象表示压缩包放在哪里(压缩包的父级路径)
File destParent = src . getParentFile (); //D:\\
//3.创建File对象表示压缩包的路径
File dest = new File ( destParent , src . getName () + ".zip" );
//4.创建压缩流关联压缩包
ZipOutputStream zos = new ZipOutputStream ( new FileOutputStream ( dest ));
//5.获取src里面的每一个文件,变成ZipEntry对象,放入到压缩包当中
toZip ( src , zos , src . getName ()); //aaa
//6.释放资源
zos . close ();
}
/*
* 作用:获取src里面的每一个文件,变成ZipEntry对象,放入到压缩包当中
* 参数一:数据源
* 参数二:压缩流
* 参数三:压缩包内部的路径
* */
public static void toZip ( File src , ZipOutputStream zos , String name ) throws IOException {
//1.进入src文件夹
File [] files = src . listFiles ();
//2.遍历数组
for ( File file : files ) {
if ( file . isFile ()){
//3.判断-文件,变成ZipEntry对象,放入到压缩包当中
ZipEntry entry = new ZipEntry ( name + "\\" + file . getName ()); //aaa\\no1\\a.txt
zos . putNextEntry ( entry );
//读取文件中的数据,写到压缩包
FileInputStream fis = new FileInputStream ( file );
int b ;
while (( b = fis . read ()) != - 1 ){
zos . write ( b );
}
fis . close ();
zos . closeEntry ();
} else {
//4.判断-文件夹,递归
toZip ( file , zos , name + "\\" + file . getName ());
// no1 aaa \\ no1
}
}
}
}
commons-io是apache开源基金组织提供的一组有关IO操作的开源工具包。
作用:提高io流开发效率。
Commons-io使用步骤
在项目中创建一个文件夹:lib 将jar包复制粘贴到lib文件夹内 右键点击jar包,选择add as Library,点击ok 在类中导包使用 Fileutils类 (文件/文件夹相关) 说明 static voidcopyFile(File srcFile,FiledestFile) 复制文件 static void copyDirectory(File srcDir,File destDir) 复制文件夹 static void copyDirectoryToDirectory(File srcDir,File destDir) 复制文件夹 static void deleteDirectory(File directory) 删除文件夹 static void cleanDirectory(File directory) 清空文件夹 static String readFileToString(File file,Charset encoding) 读取文件中的数据变成成字符串 static void write(File fileCharSequence dataString encoding) 写出数据
IOUtils类 (流相关相关) 说明 public static int copy(InputStream input,OutputStream output) 复制文件 public staticint copyLarge(Reader input,Writer output) 复制大文件 publicstaticStringreadLines(Readerinput) 读取数据 public static void write(string data,OutputStream output) 写出数据
1
2
3
File src = new File ( "a.txt" );
File dest = new File ( "b.txt" );
FileUtils . copyFile ( src , dest );
Hutool工具包
相关类 说明 IoUti 流操作工具类 FileUtil 文件读写和操作的工具类 FileTypeUtil 文件类型判断工具类 WatchMonitor 目录、文件监听 ClassPathResource 针对ClassPath中资源的访问封装 FileReader 封装文件读取 lFileWriter 封装文件写入
线程
线程是操作系统能够进行运算调度的最小单位。他被包含在进程之中,是进程中的实际运作单位。
进程
进程是程序的基本执行实体。
多线程两个概念
并发:在同一个时刻,有多个指令在单个CPU上交替执行
并行:在同一个时刻,有多个指令在多个CPU上同时执行
多线程的实现方式
继承Thread类的方式进行实现 实现Runnable接口的方式进行实现 利用Callable接口和Future接口方式实现 继承Thread类的方式进行实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
//1.定义一个类继承Thread
public class MyThread extends Thread {
//2.重写run方法
@Override
public void run () {
//书写线程要执行的代码
for ( int i = 0 ; i < 100 ; i ++ ) {
System . out . println ( "hello world!" );
}
}
}
public class ThreadDemo {
public static void main ( String [] args ) {
//3.创建子类对象
MyThread mt = new MyThread ();
//开启线程
mt . start ();
}
}
实现Runnable接口的方式进行实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
//1.定义一个类实现Runnable接口
public class MyRun implements Runnable {
//2.重写run方法
@Override
public void run () {
System . out . println ( "hello world" );
}
}
public class ThreadDemo2 {
public static void main ( String [] args ) {
//3.创建类对象-->表示要执行的任务
MyRun mr = new MyRun ();
//4.创建线程对象
Thread t1 = new Thread ( mr );
//开启线程
t1 . start ();
}
}
利用Callable接口和Future接口方式实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
//1.创建一个类实现callable接口
public class MyCallable implements Callable < Integer > {
//2.重写call(有返回值,表示多线程运行的结果)
@Override
public Integer call () throws Exception {
int sum = 0 ;
for ( int i = 0 ; i < 100 ; i ++ ) {
sum += i ;
}
return sum ;
}
}
public class ThreadDemo3 {
public static void main ( String [] args ) throws ExecutionException , InterruptedException {
//3.创建类对象-->表示多线程要执行的任务
MyCallable mc = new MyCallable ();
//4.创建FutureTask对象,管理多线程运行的结果
FutureTask < Integer > ft = new FutureTask <> ( mc );
//5.创建Thread对象(表示线程)
Thread t1 = new Thread ( ft );
t1 . start ();
//6.获取多线程运行结果
int result = ft . get ();
System . out . println ( result );
}
}
多线程三种实现方式对比
优点 缺点 继承Thread类的方式进行实现 编程简单,可以直接使用Thread类中的方法 可拓展性差,不能再继承其他的类 实现Runnable接口的方式进行实现 拓展性强,实现接口的同时可以继承其他类 编程复杂,不能直接使用Thread类中方法 利用Callable接口和Future接口实现 拓展性强,实现接口的同时可以继承其他类 编程复杂,不能直接使用Thread类中方法
常见的成员方法
方法名称 说明 String getName() 返回此线程的名称 void setName(String name) 设置线程的名字(构造方法也可以设置名字) static Thread currentThread() 获取当前线程的对象 static void sleep(long time) 让线程休眠指定的时间,单位为毫秒 setPriority(int newPriority) 设置线程的优先级 final int getPrority() 获取线程的优先级 final void setDaemon(boolean on) 设置为保护线程 public static void yield() 出让线程/礼让线程 public static void join() 插入线程/插队线程
即使没有给线程设置名字,线程也是有默认名字的。格式Thread-x(x为序号)。想要给线程设置名字除了set方法也可以调用构造方法。
JVM虚拟机启动之后会自动启动多条线程,其中有一条线程叫做Main线程,作用是调用main方法,并执行里面的代码。
Java中线程优先级分为1-10,默认为5.
当其他的非守护线程执行完毕之后,守护线程也会陆续结束 。
线程的生命周期
线程的生命周期
同步代码块 :把共享的数据代码锁起来。
1
2
3
synchronized ( 锁 ) {
操作共享数据的代码
}
特点1:锁默认打开,当有一个线程执行,锁自动关闭。
特点2:线程内代码执行完毕后锁自动打开。
同步方法 :把synchronized关键字加到方法上。
1
修饰符 synchronized 返回值类型 方法名 ( 方法参数 ) {...}
特点1:同步方法是锁住方法里面所有的代码
特点2:锁对象不能自己指定(非静态:this 静态:当前类的字节码对象)
lock锁
1
Lock lock = new ReentrantLock ();
生产者和消费者模型(等待唤醒机制)
方法名称 说明 void wait() 当前线程等待,直到被其他线程唤醒 void notify() 随机唤醒单个线程 void notifyAll() 唤醒所有线程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
//锁
public class Desk {
//定义一个标记
//true 就表示桌子上有汉堡包的,此时允许吃货执行
//false 就表示桌子上没有汉堡包的,此时允许厨师执行
//flag -->同步锁
public static boolean flag = false ;
//汉堡包的总数量
public static int count = 10 ;
//锁对象 -->互斥锁 mutex
public static final Object lock = new Object ();
}
//生产者类
public class Cooker extends Thread {
// 生产者步骤:
// 1,判断桌子上是否有汉堡包
// 如果有就等待,如果没有才生产。
// 2,把汉堡包放在桌子上。
// 3,叫醒等待的消费者开吃。
@Override
public void run () {
while ( true ){
synchronized ( Desk . lock ){
if ( Desk . count == 0 ){
break ;
} else {
if ( ! Desk . flag ){
//生产
System . out . println ( "厨师正在生产汉堡包" );
Desk . flag = true ;
Desk . lock . notifyAll ();
} else {
try {
Desk . lock . wait ();
} catch ( InterruptedException e ) {
e . printStackTrace ();
}
}
}
}
}
}
}
//消费者类
public class Foodie extends Thread {
@Override
public void run () {
// 1,判断桌子上是否有汉堡包。
// 2,如果没有就等待。
// 3,如果有就开吃
// 4,吃完之后,桌子上的汉堡包就没有了
// 叫醒等待的生产者继续生产
// 汉堡包的总数量减一
//套路:
//1. while(true)死循环
//2. synchronized 锁,锁对象要唯一
//3. 判断,共享数据是否结束. 结束
//4. 判断,共享数据是否结束. 没有结束
while ( true ){
synchronized ( Desk . lock ){
if ( Desk . count == 0 ){
break ;
} else {
if ( Desk . flag ){
//有
System . out . println ( "吃货在吃汉堡包" );
Desk . flag = false ;
Desk . lock . notifyAll ();
Desk . count -- ;
} else {
//没有就等待
//使用什么对象当做锁,那么就必须用这个对象去调用等待和唤醒的方法.
try {
Desk . lock . wait ();
} catch ( InterruptedException e ) {
e . printStackTrace ();
}
}
}
}
}
}
}
//测试类
public class Demo {
public static void main ( String [] args ) {
/*消费者步骤:
1,判断桌子上是否有汉堡包。
2,如果没有就等待。
3,如果有就开吃
4,吃完之后,桌子上的汉堡包就没有了
叫醒等待的生产者继续生产
汉堡包的总数量减一*/
/*生产者步骤:
1,判断桌子上是否有汉堡包
如果有就等待,如果没有才生产。
2,把汉堡包放在桌子上。
3,叫醒等待的消费者开吃。*/
Foodie f = new Foodie ();
Cooker c = new Cooker ();
f . start ();
c . start ();
}
}
等待唤醒机制
阻塞队列继承结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
public class Cooker extends Thread {
private ArrayBlockingQueue < String > bd ;
public Cooker ( ArrayBlockingQueue < String > bd ) {
this . bd = bd ;
}
// 生产者步骤:
// 1,判断桌子上是否有汉堡包
// 如果有就等待,如果没有才生产。
// 2,把汉堡包放在桌子上。
// 3,叫醒等待的消费者开吃。
@Override
public void run () {
while ( true ) {
try {
bd . put ( "汉堡包" );
System . out . println ( "厨师放入一个汉堡包" );
} catch ( InterruptedException e ) {
e . printStackTrace ();
}
}
}
}
public class Foodie extends Thread {
private ArrayBlockingQueue < String > bd ;
public Foodie ( ArrayBlockingQueue < String > bd ) {
this . bd = bd ;
}
@Override
public void run () {
// 1,判断桌子上是否有汉堡包。
// 2,如果没有就等待。
// 3,如果有就开吃
// 4,吃完之后,桌子上的汉堡包就没有了
// 叫醒等待的生产者继续生产
// 汉堡包的总数量减一
//套路:
//1. while(true)死循环
//2. synchronized 锁,锁对象要唯一
//3. 判断,共享数据是否结束. 结束
//4. 判断,共享数据是否结束. 没有结束
while ( true ) {
try {
String take = bd . take ();
System . out . println ( "吃货将" + take + "拿出来吃了" );
} catch ( InterruptedException e ) {
e . printStackTrace ();
}
}
}
}
public class Demo {
public static void main ( String [] args ) {
ArrayBlockingQueue < String > bd = new ArrayBlockingQueue <> ( 1 );
Foodie f = new Foodie ( bd );
Cooker c = new Cooker ( bd );
f . start ();
c . start ();
}
}
线程状态
当线程抢到CPU执行权后,虚拟机将线程交给操作系统执行。
线程内存图
线程内存图
线程池原理
创建一个池子,池子中是空的。 提交任务时,池子会创建新的线程对象,任务执行完毕,线程归还给池子,下回再次提交任务时,不需要创建新的线程,直接复用已有的线程即可。 但是如果提交任务时,池子中没有空闲线程,也无法创建新的线程,任务就会排队等待。 线程池实现
创建线程池 提交任务 所有任务全部执行完毕,关闭线程池 Executors:线程池的工具类通过调用方法返回不同类型的线程池对象。
方法名称 说明 public static ExecutorService newCachedThreadPool() 创建一个没有上限的线程池 public static ExecutorService newFixedThreadPool(int nThreads) 创建有上限的线程池
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
//1.获取线程池对象
ExecutorService pool1 = Executors . newCachedThreadPool ();
//2.提交任务
pool1 . submit ( new MyRunnable ());
//3.销毁线程池
pool1 . shutdown ();
//任务
//1.定义一个类实现Runnable接口
public class MyRun implements Runnable {
//2.重写run方法
@Override
public void run () {
System . out . println ( "hello world" );
}
}
线程池多大合适?
CPU密集型运算:最大并行数+1
I/O密集型运算:最大并行数*期望CPU利用率 *总时间/CPU计算时间
网络编程概述
网络编程:计算机与计算机之间通过网络进行数据传输。
软件架构
软件架构
软件架构优缺点
网络编程三要素
IP:设备在网络中的地址,是唯一表示
端口号:应用程序在设备中的唯一标识
协议:数据在网络中的传输规则,常见的有UDP、TCP、http、https、htp
InetAddress类
1
2
3
4
5
6
7
8
//1.获取InetAddress对象
InetAddress host = InetAddress . getByName ( "Interstellar×HUAWEIScentificVersion" );
//2.调用方法
String name = host . getHostName ();
String ip = host . getHostAddress ();
System . out . println ( ip );
System . out . println ( name );
System . out . println ( host );
UDP通信程序
发送步骤:
创建DatagramSocket对象 数据打包(DatagramPacket) 发送数据 释放资源 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
/*
** 发送程序
*/
//1.创建对象
//细节:创建对象的同时会绑定对应的端口
//空参:随机 有参:指定窗口
DatagramSocket ds = new DatagramSocket ();
//2.打包数据
String str = "你好世界!" ;
byte [] buffer = str . getBytes ();
InetAddress address = InetAddress . getByName ( "127.0.0.1" );
int port = 20080 ;
DatagramPacket dp = new DatagramPacket ( buffer , buffer . length , address , port );
//3.发送数据
ds . send ( dp );
//4.释放资源
ds . close ();
接收步骤:
创建DatagramSocket对象 接收打包好的数据 解析数据包 释放资源 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
/*
** 接收程序
*/
//1.创建DatagramSocket对象
//细节:绑定端口与发送端目的端口一致
DatagramSocket ds = new DatagramSocket ( 20080 );
//2.接收数据包
byte [] buffer = new byte [ 1024 ] ;
DatagramPacket dp = new DatagramPacket ( buffer , buffer . length );
//该方法是阻塞的
ds . receive ( dp );
//3.解析数据包
byte [] data = dp . getData ();
int length = dp . getLength ();
InetAddress address = dp . getAddress ();
int port = dp . getPort ();
System . out . println ( "文字内容为" + new String ( data , 0 , length ));
System . out . println ( Arrays . toString ( buffer ));
System . out . println ( "端口号" + port );
//4.释放资源
ds . close ();
UDP三种通信方式
单播 上述案例便是单播 组播 组播地址:224.0.0.0-239.255.255.255 其中224.0.0.0-224.0.0.255是预留的组播地址 广播 225.255.255.255 TCP通信协议
TCP通信协议是一种可靠的网络协议,他在通信的两端各简历一个Socket对象,通信之前必须保证连接已经建立。通过Socket产生的IO流进行网络通信。
客户端步骤:
创建客户端的Socket对象与指定服务端连接。 获取输出流,写数据。 释放资源。 服务端步骤:
创建服务器端的Socket对象 监听客户端连接,返回一个socket对象 获取输入流,读数据,并把数据显示在控制台 释放资源 什么是反射?
反射允许对封装的字段,方法和构造函数的信息进行编程访问。 IDE中的代码提示、参数提示等就是利用反射实现的。
获取class对象的三种方式
Class.forName(“类名”) 源代码阶段使用,最为常用 类名.class 加载阶段使用,一般用于参数传递 对象.getClass() 运行阶段使用 当有类的对象时才进行使用 利用反射获取构造方法
Class类中用于获取构造方法的方法
Constructorl]getConstructors():返回所有公共构造方法对象的数组
Constructorl]getDeclaredConstructors(): 返回所有构造方法对象的数组
Constructor < T > getConstructor (Class …parameterTypes):返回单个公共构造方法对象
Constructor< T >getDeclaredConstructorClass.. parameterTypes): 返回单个构造方法对象
Constructor类中用于创建对象的方法
TnewInstance(Object…initargs):根据指定的构造方法创建对象
setAccessible(boolean flag):设置为true表示取消访问检查
利用反射获取成员变量
Class类中用于获取成员变量的方法
FieldgetFields():返回所有公共成员变量对象的数组
FieldgetDeclaredFields():返回所有成员变量对象的数组
FieldgetField(Stringname):返回单个公共成员变量对象
FieldgetDeclaredField(Stringname):返回单个成员变量对象
Field类中用于创建对象的方法
void set(Object obj, Object value):赋值
Object get(Object obi) 获取值。
利用反射获取成员方法
Class类中用于获取成员方法的方法
MethodllgetMethods():返回所有公共成员方法对象的数组,包括继承的
MethodilgetDeclaredMethods(): 返回所有成员方法对象的数组,不包括继承的
MethodgetMethod(String name,Class… parameterTypes): 返回单个公共成员方法对象
MethodgetDeclaredMethod(String name,Class… parameterTypes): 返回单个成员方法对象
Method类中用于创建对象的方法
Object invoke(Object obj,Object…args):运行方法
参数一:用obj对象调用该方法
参数二:调用方法的传递的参数(如果没有就不写)
返回值:方法的返回值(如果没有就不写)
反射的作用
获取一个类里面所有的信息,获取了之后在执行其他的业务逻辑 结合配置文件,动态的创建对象并调用方法